Dear all,
I am experiencing issues when using pvbatch in a HPC environment. Here I present 2 examples :
Here I have uploaded a streaklines snapshot where some streaklines become invisible when they pass through certain regions (my mesh blocks). The rate, amount and position of the regions of disappearance change with the number of CPUs that I am using for the rendering.

However when the post-process is carried out in a local laptop using multicore postprocessing the result is the following ;

The next case is a line graph where there is a significant lack of resolution in the line in spite of the fact that the axis labels present the right resolution.
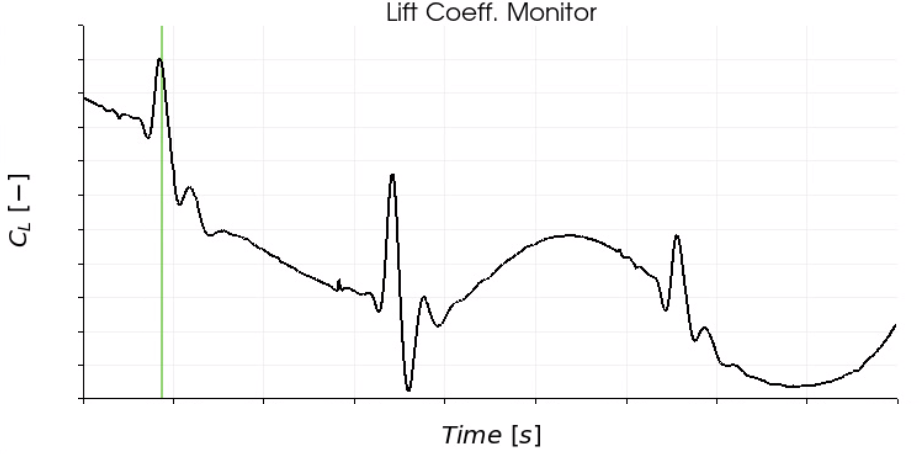
And this is the above case executed in the same laptop, the line becomes much smoother :

The CPUs of the HPC center where I am undertaking these jobs are Intel® Skylake 2,3 Ghz 2x18-cores.
I am calling pvbatch as,
time pvbatch --force-offscreen-rendering $my_script.py
My guess is that I am not loading the right additional modules/drivers to execute the paraview/pvbatch-5.9.0 module correctly in the slurm-job. Is there any module/driver that I should load when producing data for visualization? Thank you in advance for your time.
