I am passing data on a rectilinear grid to Catalyst for in-situ visualization.
I set up the grid in the function createcpdata_ in the attached file FECxx.cxx (4.2 KB)
I have the python-coprocessor script currently output the data using the XMLPRectilinearGridWriter (see the attached file coproc.py (2.8 KB)).
This generates a main .pvtr file not holding any data but referring to the multiple .vtr files in a subfolder which are generated by the different MPI ranks.
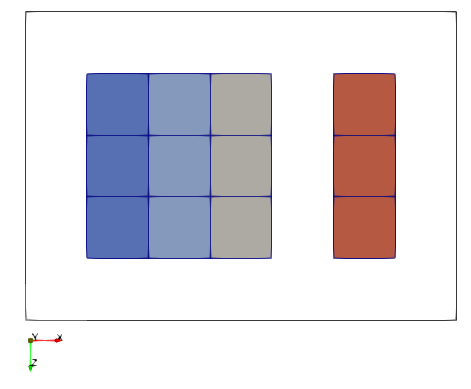
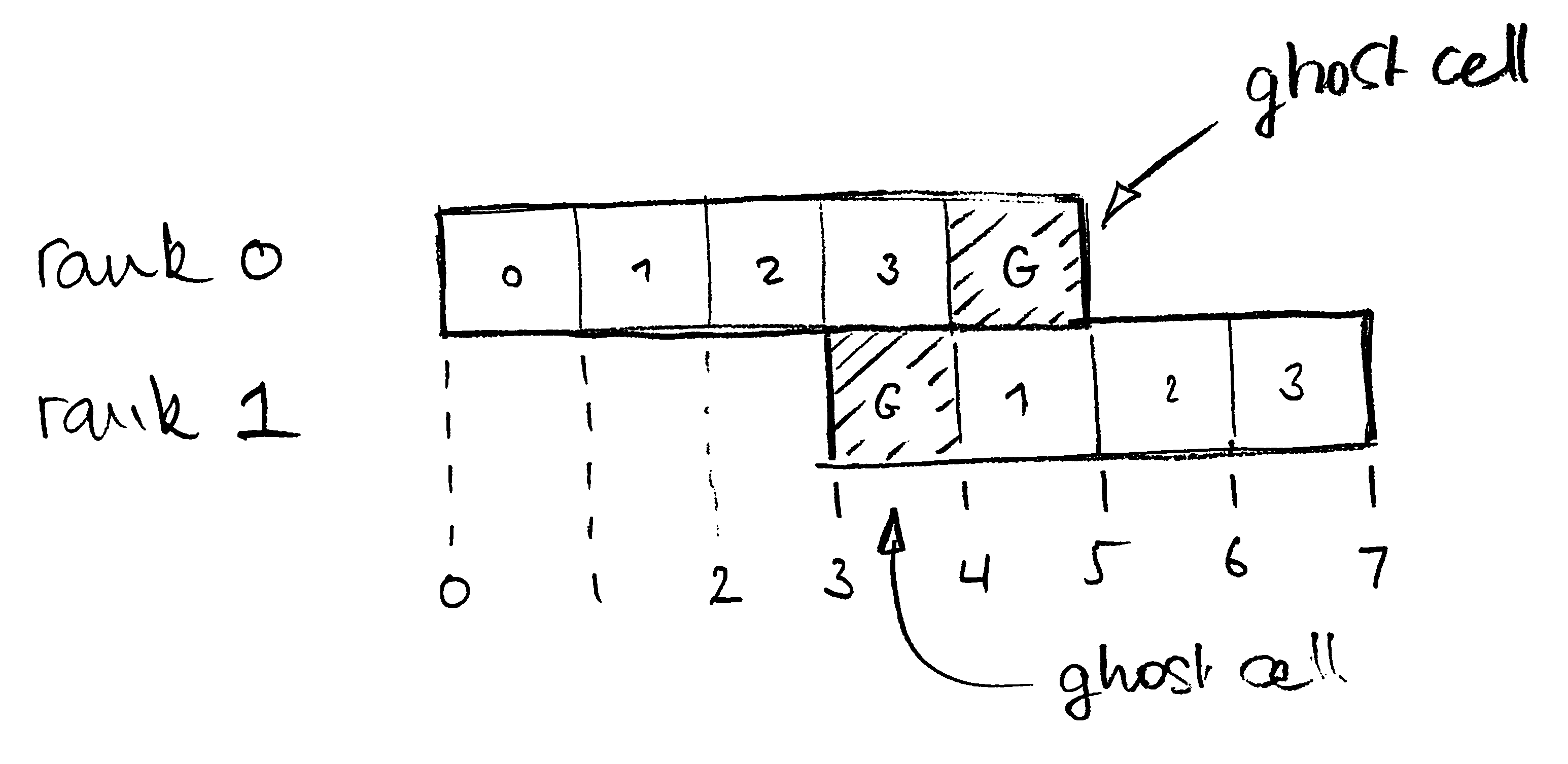
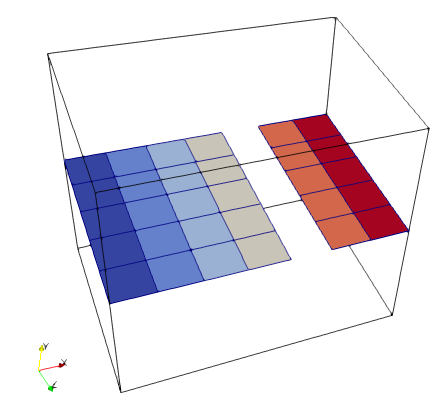
For debugging purpose I am processing a small dataset using two processes, and 7×6×5 cells in total. The first process gets 5×6×5 cells, the second one gets 4×6×5 cells. These overlap by two layers in the x-direction, since the cells of each process contain one layer of ghost cells on all six sides.
When loading the main .pvtr file I am confronted with missing cells as can by seen in the following slice:
The blueish cells belong to rank0. I expect to see 3×3 cells, that’s fine. For some reason, the cells written by rank1 are not entirely visible. Here the first layer of cells normal to the x-axis is lacking.
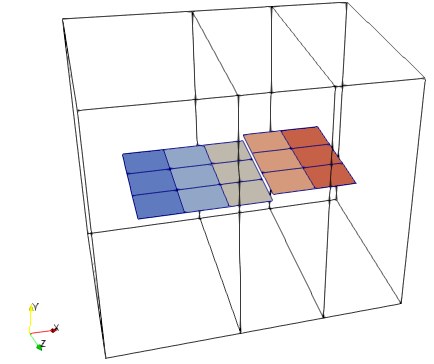
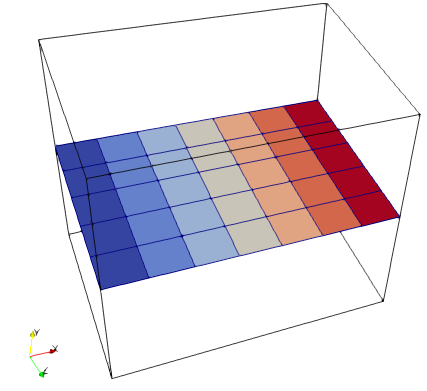
When loading the two corresponding .vtr files individually into Paraview, then I get a seamless representation with only the ghost cells being hidden. In the following visualization I sliced the data of the two .vtr files at slightly different levels of y:
Here is the data (.pvtr and .vtr files): data.zip (1.7 KB)
Should I open an issue somewhere else? Is there a workaround?
I can reproduce this behavior in Paraview 5.5.2 and 5.6.0
I noticed that no information about ghost cells is written to any output .pvtr/.vtr file but the very first one that my coprocessor creates. Maybe this is gives a clue to anyone.
I also wondered if maybe my declaration of ghostcells at the six sides of the global simulation domain is incompatible with Paraviews’ concept of ghost cells, since there are no overlapping subdomains in these regions. So I excluded these cells from being marked as ghost cells, but the issue remains.
.pvtr file on the left, the two .vtr files on the right.
1. Changed GhostLevel="0" to GhostLevel="1" or GhostLevel="2"
No impact:
2. Changed the extent of the first piece from Extent="0 5 0 6 0 5" to Extent="0 4 0 6 0 5"
This fixes the representation regardless of what value GhostLevel is set to.
But why is that so?
In this official Kitware presentation I am taught on slide 66 that an extent denotes the indices of the points limiting the cells. Changing the maximum extent of the first rank’s part of the grid from 5 to 4 contradicts this concept. (Do also not get confused that on slide 67 of the presentation three columns should be painted blue instead of two)
This can’t possibly be the solution, …
because if I reduce the extent this way where the grid is defined in the catalyst adaptor function, I won’t have the right number of cells.
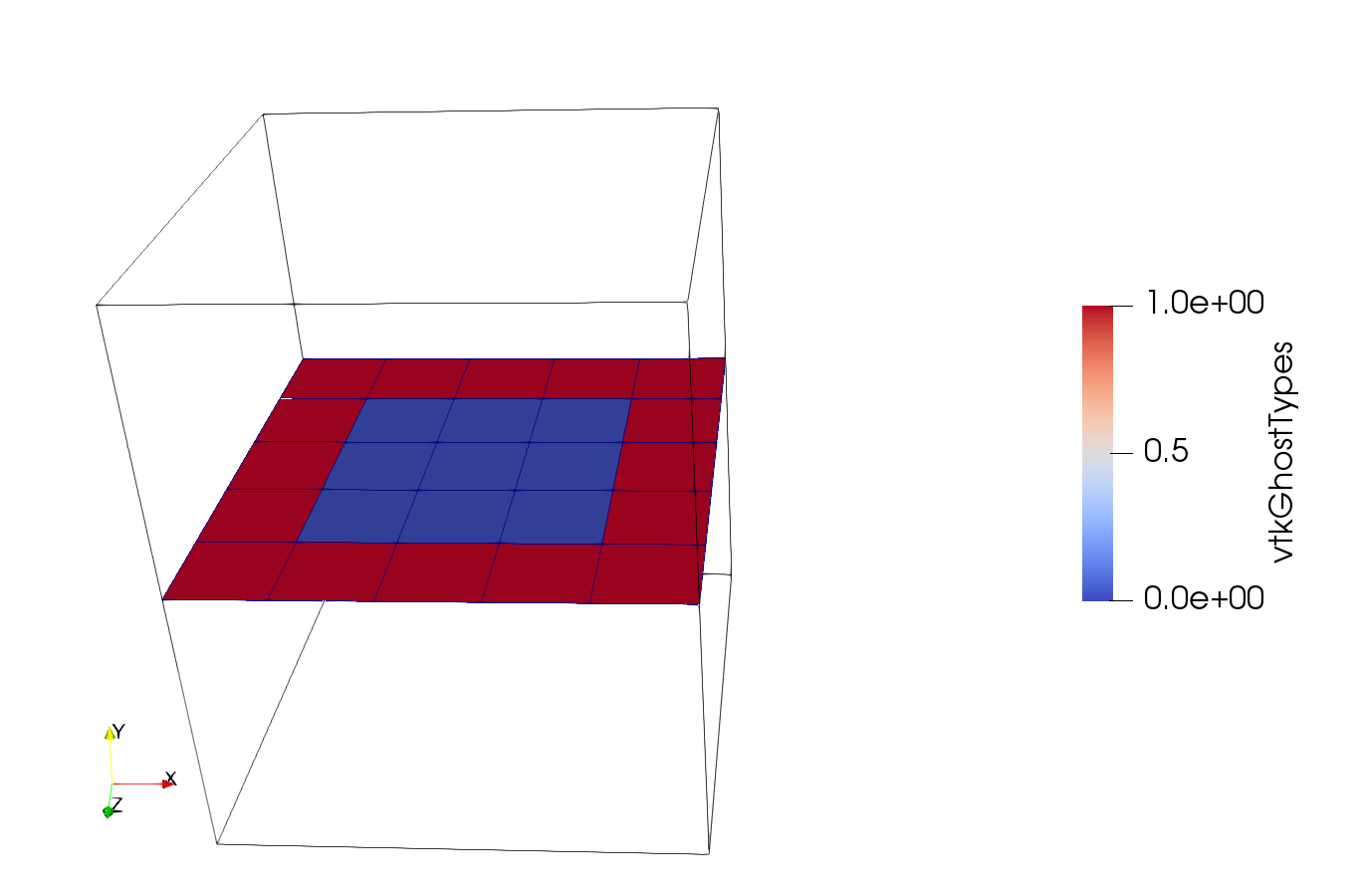
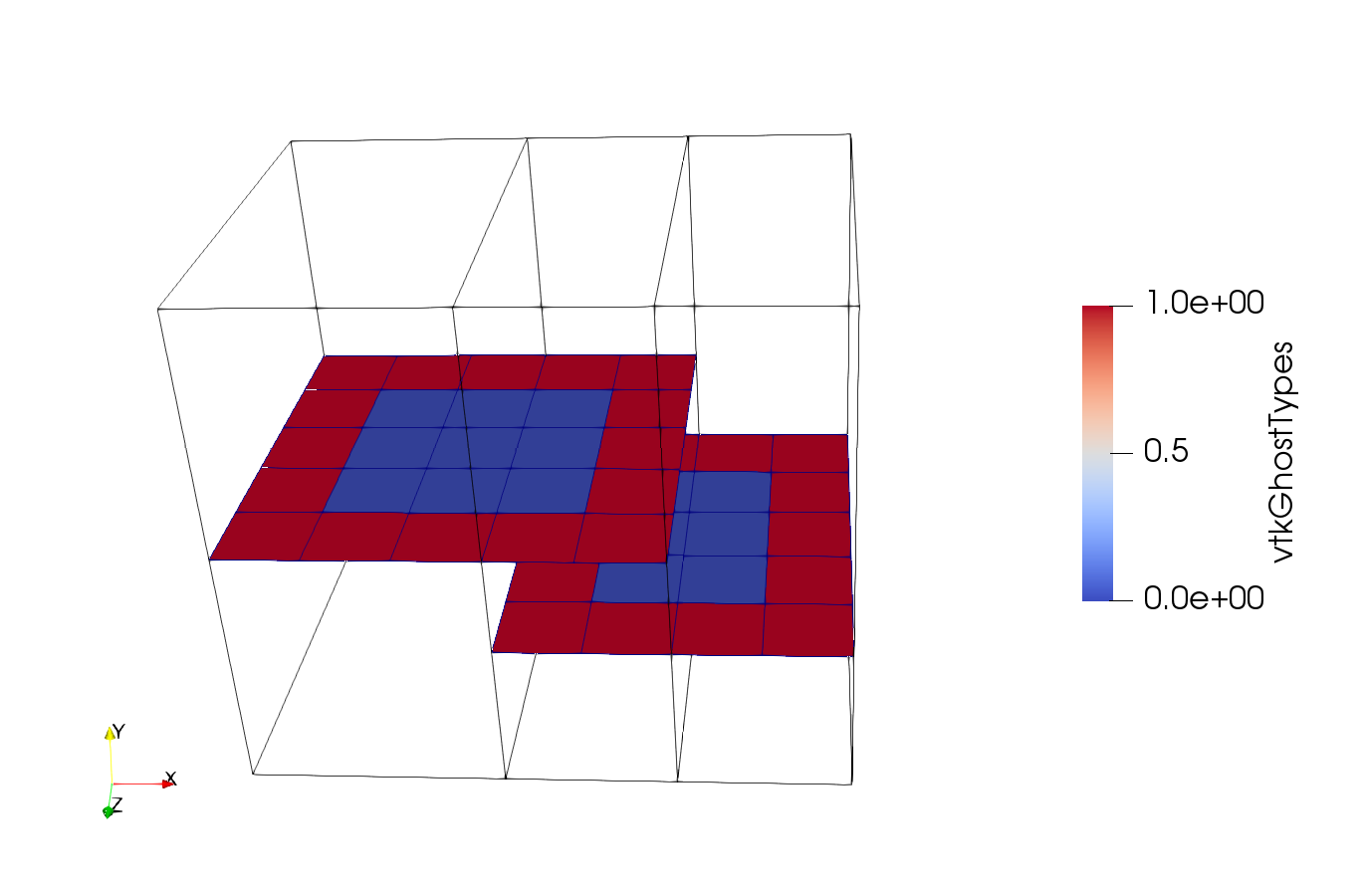
This picture shows a slice through your data twice. The first time I used the data you send and got the same slice. The second time, I modified your data by renaming vtkGhostType to vtkGhostTypes so that it is not interpreted by ParaView, and then extracted only the cells that have vtkGhostTypes 1.
Those are red. So cells are missing because are marked as ghosts.
In the attachment I included the two datasets and a ParaView state file that produces this image.
I still fail to understand why that should be so. The missing cells are marked as ghosts in pressure_20_1.vtr, true, but they are not in pressure_20_0.vtr. When viewing the combination of the two, there should not be a gap.
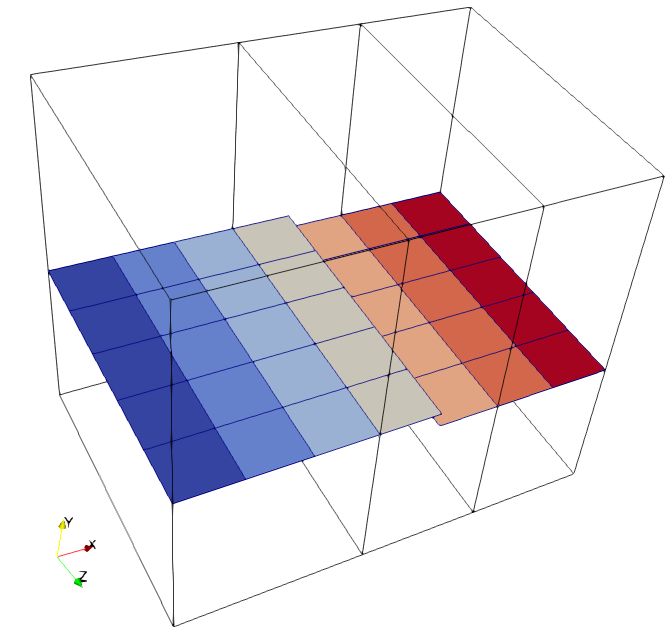
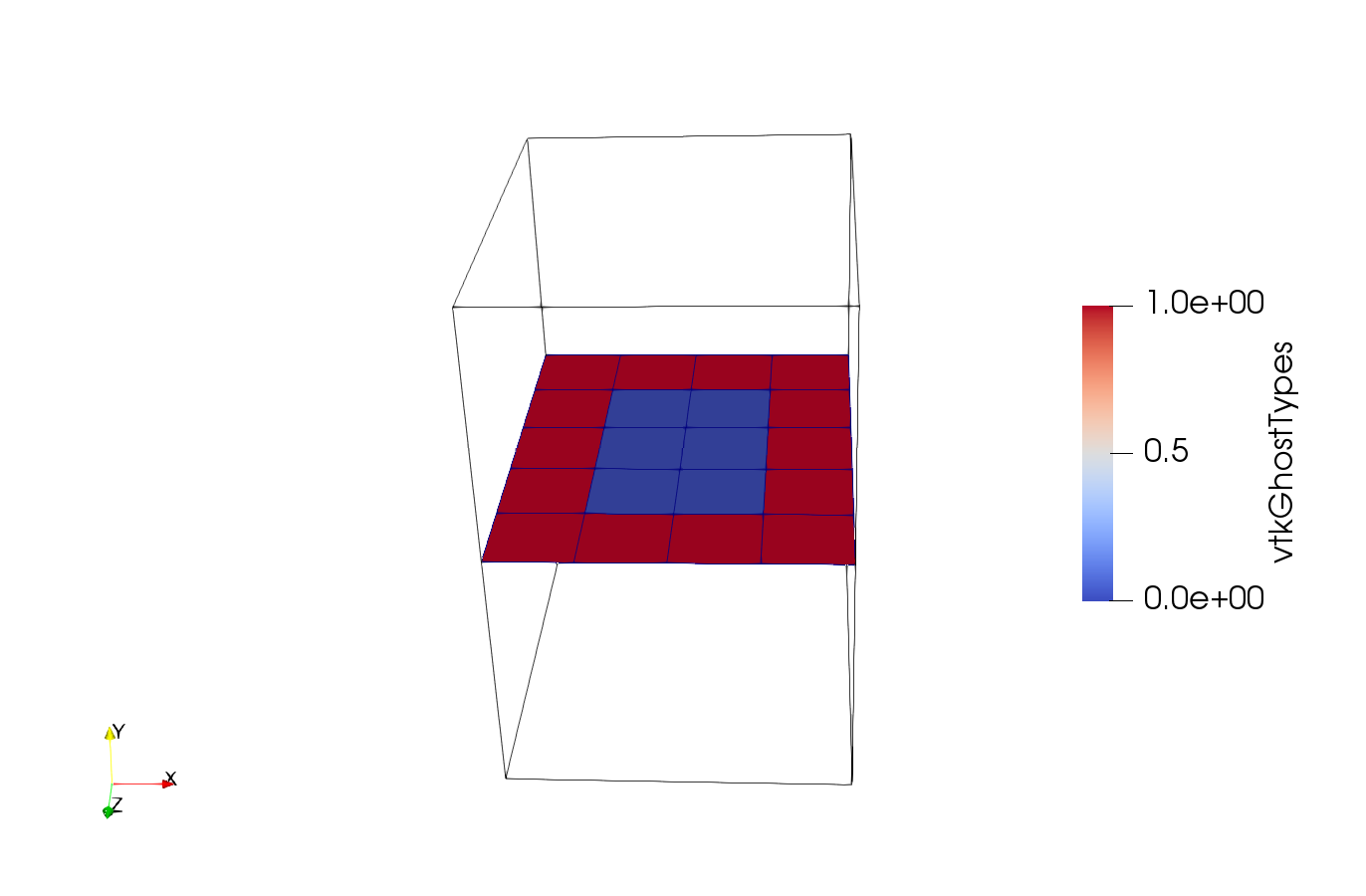
Here are screenshots where I visualize the “GhostTypes” fields you made available in the ghost.zip-file:
pressure_20_0.vtr on the left and pressure_20_1.vtr to the right:
As you can see, there is no gap.
In the position where a gap is present when viewing pressure_20.pvtr I would expect data from pressure_20_1.vtr (right) to be displayed.
We may have diverging ideas of the concept of ghost cells though.
Bastian,
You are right. This seems to be a bug in how pvtr reads two pieces on one node. I also tried to read this data on two nodes but that did not seem to work correctly either.
Here is a picture for reading the data on one node (left) as well as reading the individual pieces (right top and right bottom)