I am having trouble processing results from a simple CFD case, where the output is cell data for pressure and velocity in an exodus file.
In my case, I have a no-slip boundary condition, meaning the velocity should be zero at this boundary.
Using the ‘CellDataToPointData’ filter uses the average value of neighbouring cell centroids to calculate the velocity at each point.
This is great, except for at the no-slip boundary where the velocity becomes equal to that at the centroids of the first layer of cells. This means the velocity gradients are wrong (I believe half of what they should be), and so various other calculations are thrown out.
When the CFD code runs the simulation, I believe the boundary would have been enforced using a layer of ghost cells mirroring the velocity; however, I cannot access these ghost cells in the output file.
Is there any way to fix data values at a boundary when converting from cell data to point data, or in some other way preserve the no slip condition here? This seems like a situation which could occur when processing any finite volume simulation results.
In this instance, I want to force the velocity to be zero at a particular ‘no-slip’ boundary.
When the simulation ran, this condition was enforced, so the velocities calculated at the cell centroids are correct.
However, when converting from cell data to point data, the velocity at the nodes on this boundary become non-zero, since their velocity is taken to be the average of adjacent cell centroids. Even for the cells nearest the boundary, the cell centroids are not touching the boundary, hence these velocities are non-zero.
Ideally, I would like to specify the velocity at the boundary nodes to be zero, instead of taking the average of surrounding cells.
Hopefully this makes sense - it’s a little hard to explain without drawing things!
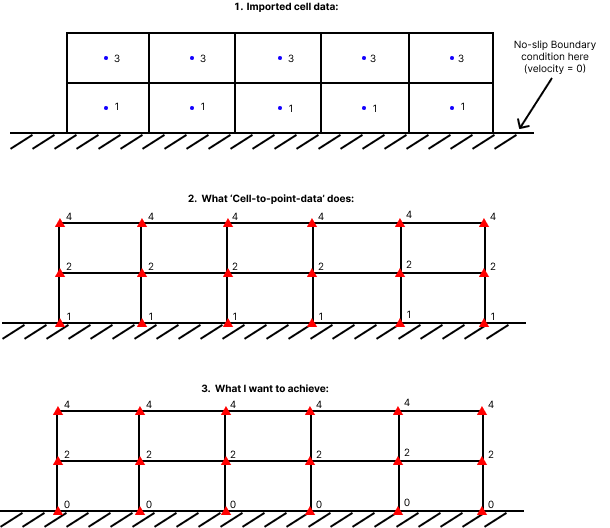
The blue dots represent cell data, which is output from a finite volume method simulation. In this simulation, some condition at the boundary was imposed (here, velocity=0), even though no values are explicitly calculated at this boundary.
The red triangles are the point data at the nodes.
The numbers are example velocity values chosen for convenience.
The problem with setting the boundary cell values to zero before converting to point data is that the second row of nodes (in the above example, those with velocity ‘2’) would then be wrong.
The main issue this is causing is that the velocity gradients are calculated incorrectly later in my pipeline. Supposing a convenient cell height of 1, we can see that the velocity gradient at the boundary in image 2 is vel_grad=1, as opposed to the correct value in image 3, which is vel_grad=2.
Hopefully this is clearer, to make sure we are speaking about the same things!
I can see the value in dealing with boundary conditions like this properly. Perhaps this is a bigger discussion in how we do cell to point. I was thinking the main exceptional location in a grid was for hanging nodes/t-junctions, but this makes me think that boundaries, which often have more nuanced details for the computational scientist, is worth contemplating for the cell to point calculation? Yes, I think there is interest here. Are there other problems linked back to cell to point?
Would setting a dedicated array with boundary condition values be working? We could do something like if the value is NaN, do nothing, otherwise, constrain.