Hello,
I wanted to check regarding the ability to alter assigned Kmeans RowID’s for better Kmeans data visualization. When running Kmeans I end up with a beautiful visualization for electrical resistivity dataset assessed, pictured below.
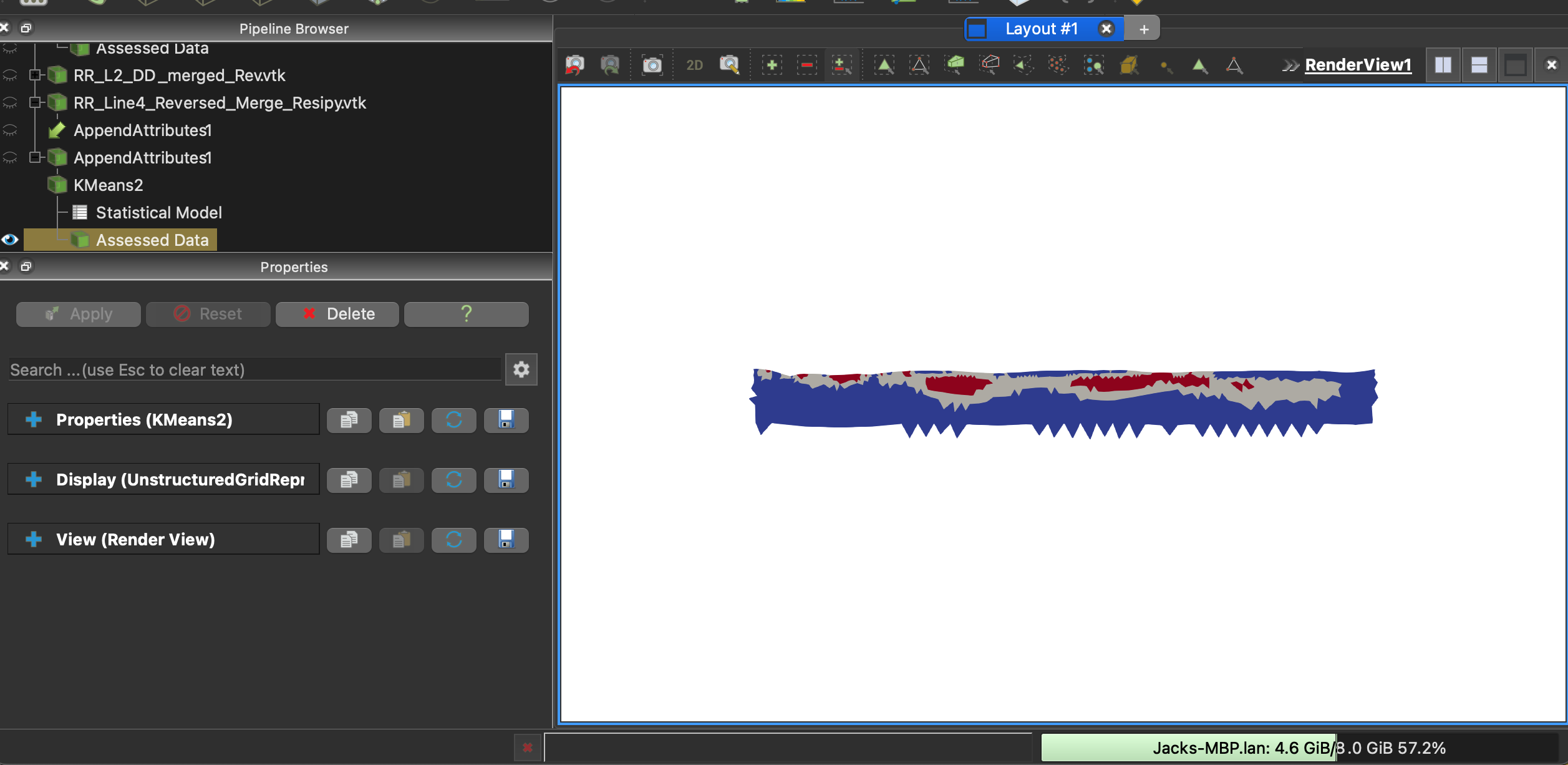
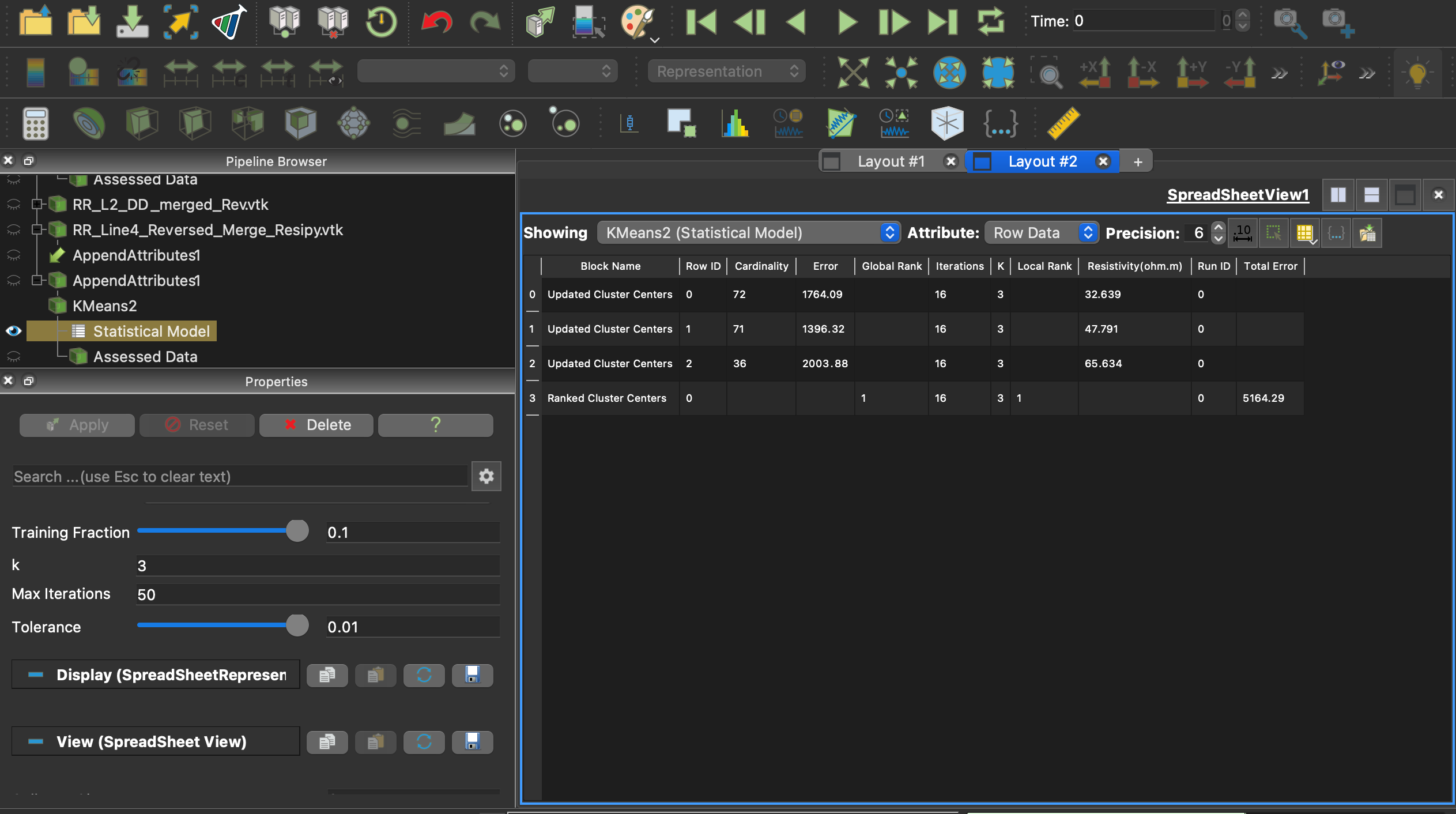
The Kmeans statistical analysis output file is here to assist with interpreting the results. Essentially my K=3 and I have three assigned output clusters in red, grey, and blue. The lowest resistivity cluster is colored blue, middle resistivity in grey, and the highest cluster values in red. RowID
When running this analysis on a second dataset I want to mimic the same clustering colors to match my previous visualization. However when I rerun the Kmeans analysis on the new dataset the output assigns the lowest resistivity cluster to the grey color, with the medium cluster being blue.
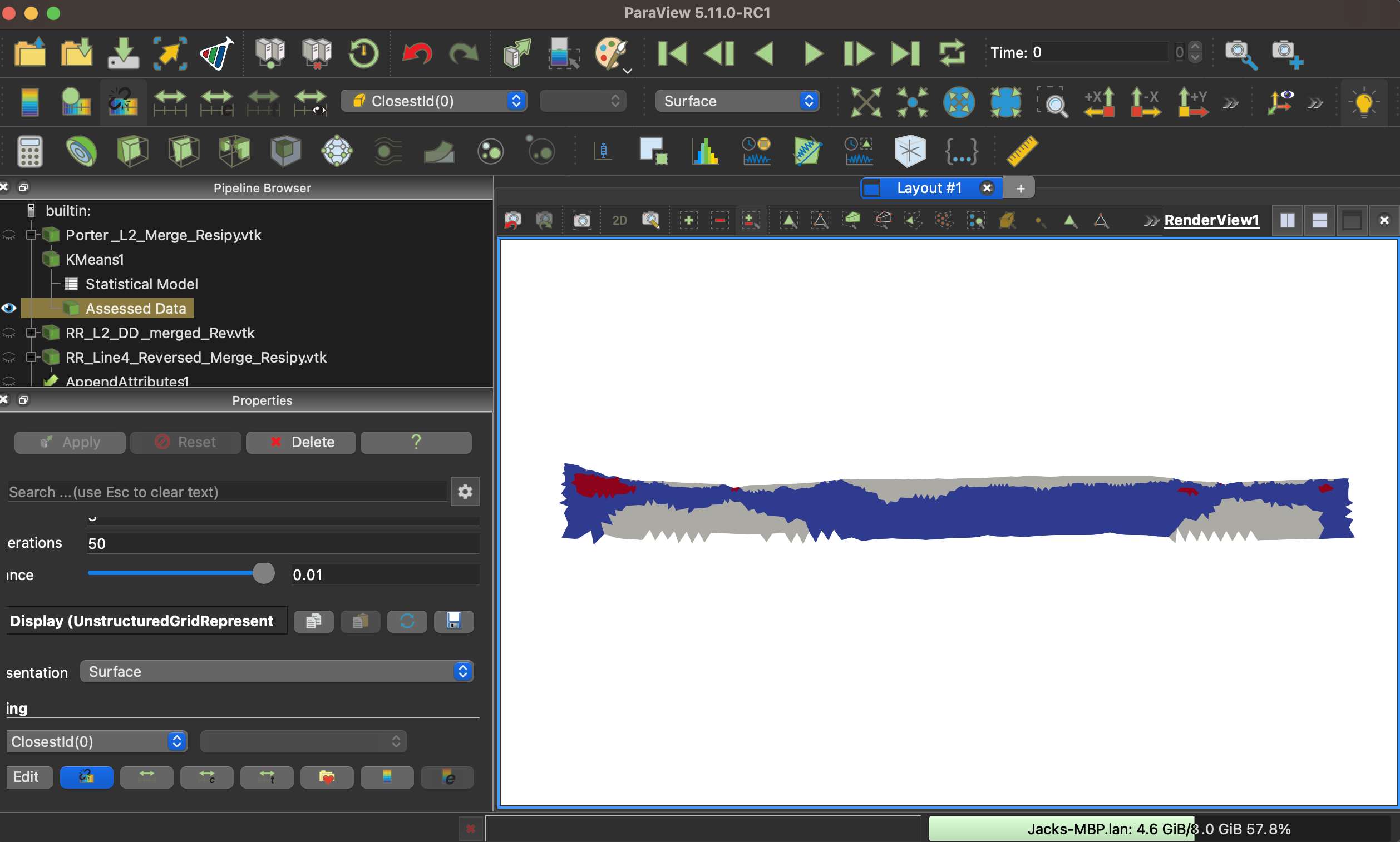
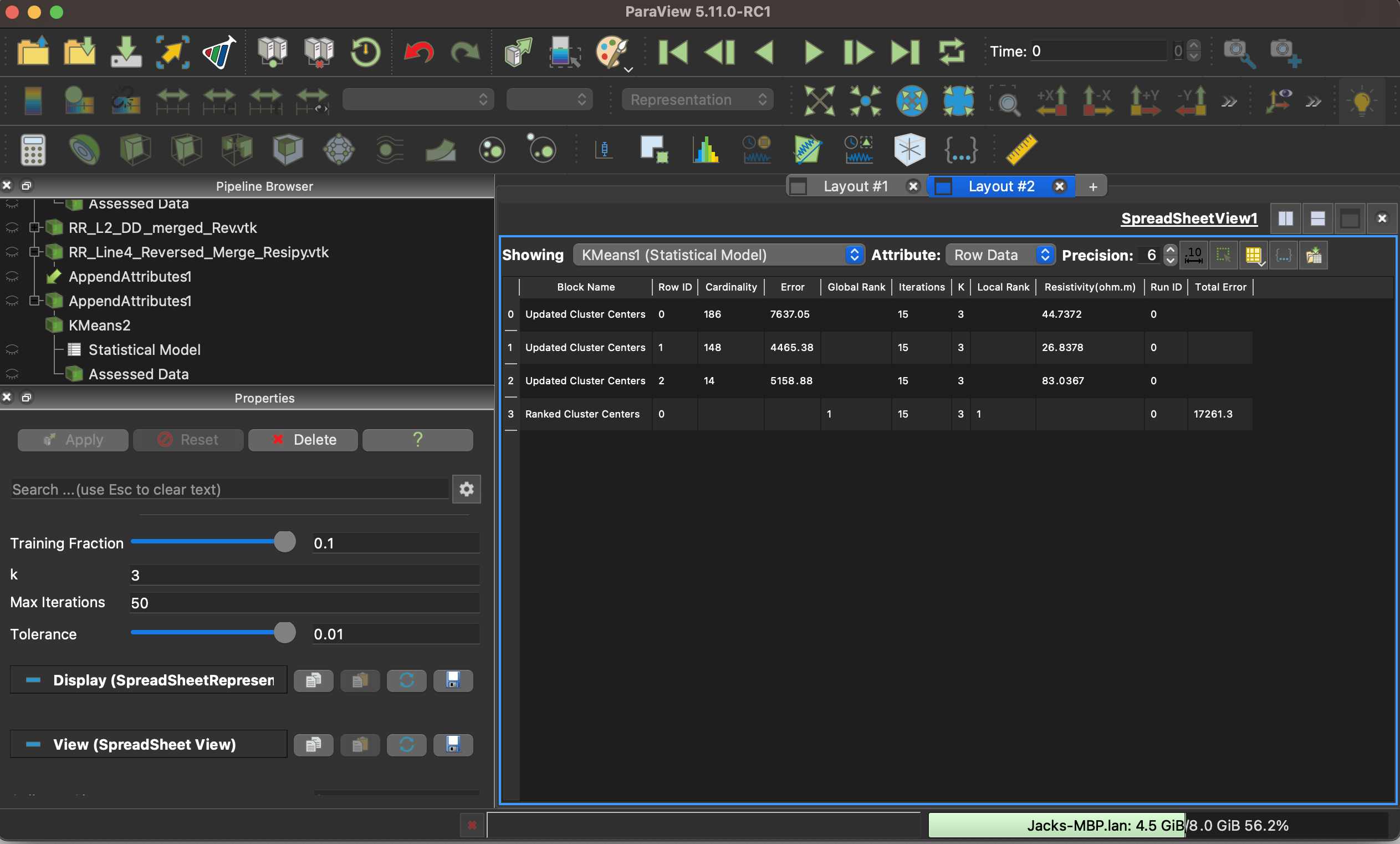
To change the color I would need to switch my RowID so RowID=0 represents my lowest resistivity cluster and RowID=1 represents my second highest resistivity cluster.
Please let me know if you have any solutions for this or if there is a solution for my color map to be changed to reflect the appropriate scaled colors in the results. Thanks for the help!
Best,
Jack