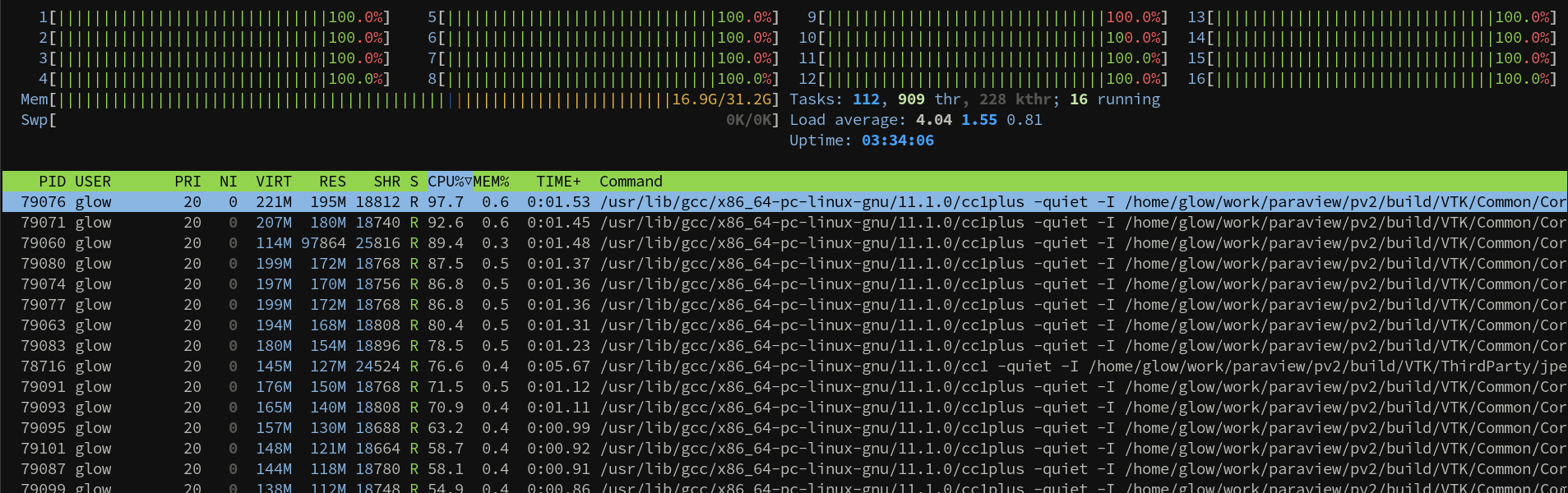
I have tried looking for information about how to take advantage of multiple cores when compiling ParaView but haven’t had any luck.
Using ninja or make spawns processses on all (or specified) cores, but I get barely more than 1 core’s worth of utilization out of the overall build. Is this just the way it is with PV or is there something I’m missing?
Thanks for taking the time to show this and confirm it for me.
For some reason I am not getting the same behaviour. It spawns a lot of gcc processes, but they each only add up to one core’s worth of CPU usage throughout the build process. If I ever get to the bottom of this I will report back. As the other reply says perhaps this is caused by IO but it’s so perfectly restricted to a single core (out of 64) that that seems unlikely.
I’ve switched architectures from ARM to x86_64 and all cores are now fully utilized. Not sure if there’s something wrong with my build tools for ARM. I also increased my disk throughput from about 200 MB/s to 500. So no conclusive answer but hopefully that’s a hint to anyone more knowledgeable coming across this.
I think you mean that you switched the machine you were compiling on from ARM to x86_64? You weren’t cross-compiling, were you? So perhaps this is a bug in ninja/gcc on ARM?