I am getting some surprising behaviour in a code which is a bit hard to describe, so I just wanted to ask to double check my assumptions.
As per my other posts I keep playing with computing connectivity in parallel. I compute in parallel some contours, run a Connectivity filter in ParaView (I am trying also vtkPConnectivityFilter in VTK through a programmable filter) and then feed into a Threshold filter, which I run through an Outline. All fun and games!
The result should be a vtkPolyData object that I want to store in a list for some additional processing on subsequent time steps. The problem I get in parallel runs is that data that are on other processors are inaccessible and I get bounding boxes of -inf, inf kind.
I am using Fetch to access the VTK object. In client-server mode Fetch gives you access to the output from a proxy and assembles the data on the client, but when I run Fetch in Catalyst I think I just get the VTK output visible to a given rank only. Is that correct?
Assuming that this is correct, I wrote a programmable filter with all the steps, but at the end I send everything to rank 0 through MPI controller. I confirm with print statements that my append filter has the correct bounding box. I still need to access this vtkPolyData so I run Fetch and somehow I get stuck with inf. I know that Fetch has a second argument which can take an integer, that will be interpreted as rank so I tried also
myoutline = Fetch(self.programmable, arg2=0)
but that didn’t change anything.
My last question is a suspicion rather that I’d like confirmed. If Fetch runs on rank 0 will it return empty set if arg=0? I’ve gone through several iterations of this and it seems that now my problem is objects which are entirely on rank 0…
Alternatively, if you could advise what’s the best way in catalyst/pvpython in parallel to access and store a concatenated output of an outline filter/vtkPolyData that may be distributed over several ranks. I don’t mind it staying distributed or all going to rank 0 as long as I can store the copy of the output and compare with the future outputs of the same pipeline. I am doing a sort of feature tracking with vtkPolyData being tracked across time steps.
I don’t know the exact answer to your question but a simple test should be trying to run pvbatch in parallel with the -sym command line option. This option results in each MPI process running the script and then pvbatch behaves very similarly to Catalyst when running Python scripts. Without the -sym argument only MPI process 0 actually runs the Python script and tells the other processes what to do, which is more like what happens in client-server mode.
This may not be the answer you’re looking for but is the way that I often debug Catalyst issues without having to actually run Catalyst.
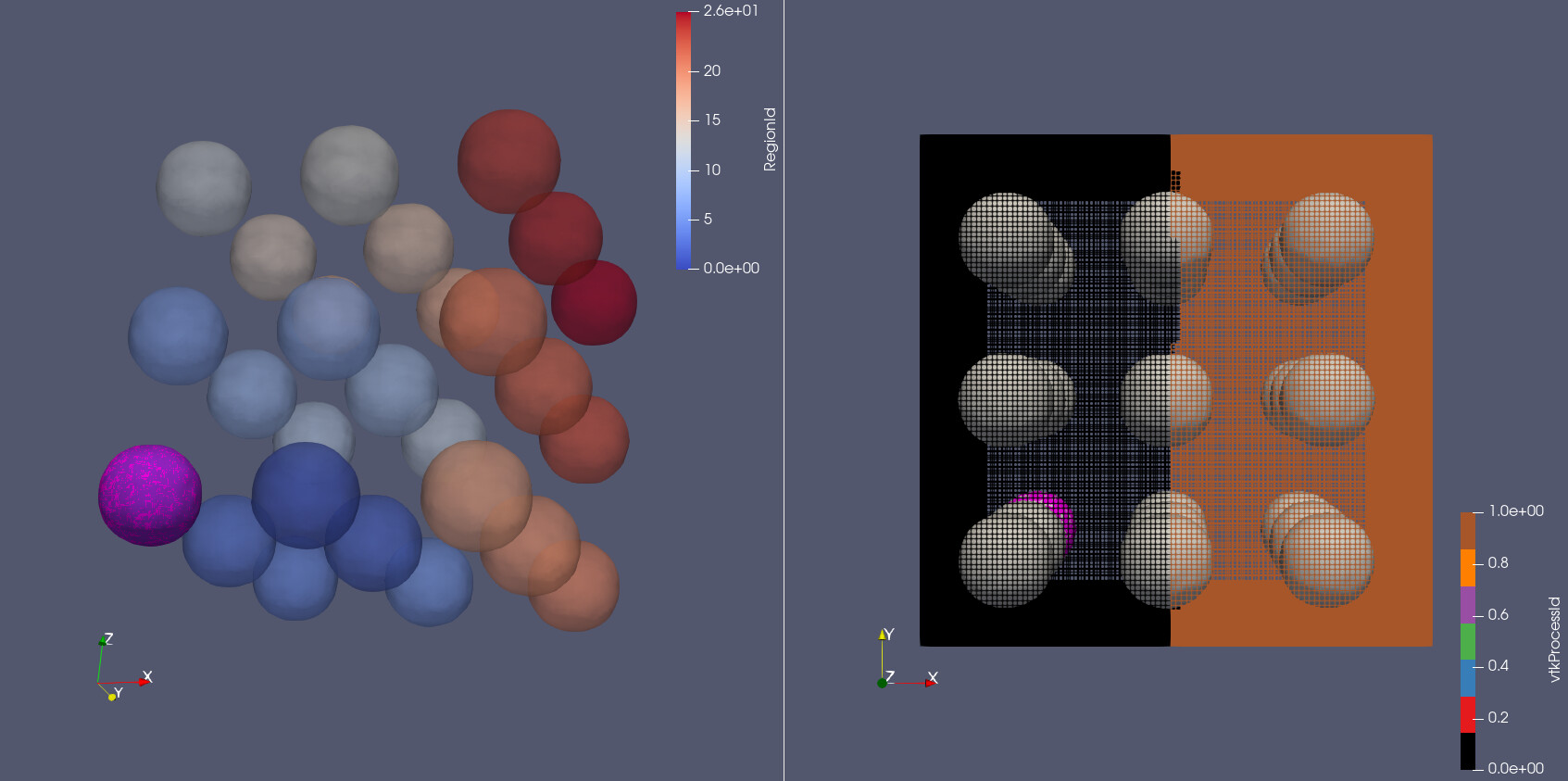
Sorry, I just want to add one picture to describe my problem better. Please see below.
I am testing on two processors and I have 27 balls. 9 on rank 0, 9 on rank 1 and 9 on the boundary. All I really want is to store their outlines somewhere and associated region ID and compare to the next time step.
The purple one is the one selected by Threshold. When I select the balls on rank 0 and Fetch the output I get infs. It seems to work fine for all balls that are not entirely on rank 0.
Personally, I don’t care much for Fetch. It’s too confusing and very cryptic. FetchData added in 5.10, IIRC, is perhaps easier since it directly delivers data from ranks of interest. It also has options to indicate if data should be gathers on all ranks or just to root node – which may be good way of you want to build the cache on root node alone. TestFetchData.py has a few examples of how to use this function.
And as Andy mentioned, testing with pvbatch --symmetric ... is indeed a good way to emulate Catalyst environment.
Thanks for this, @utkarsh.ayachit. Unfortunately, as I outlined here I am still struggling with recreating the same build with Catalyst on 5.10.x, but if you say that FetchData can sort out this problem, I will give it another go, presently.
I am just surprised that there is no other way to get a reference to VTK object. I understand ProgrammableFilter is a proxy, but we even specify vtkPolyData as output so I was looking for a clean way to get just that.