When vizualizing AMR data with 1 layer of ghost zones, the ghost zones don’t get removed as I would have expected. However, when I run the extract level filter, ghost zones are correctly removed in the output. it seems like the path amr data takes misses removing ghost zones.
To be a little more specific , in my vtkGhostType array I have marked refined cells with REFINEDCELL, ghost zones with DUPLICATECELL, and cells that are both refined and ghost cells REFINEDCELL|DUPLICATECELL. Cells marked with DUPLICATECELL are not being removed.
Thanks. After reviewing the link I’m realizing that my post was imprecise. when I said ghost cells aren’t removed, I mean that they are still being rendered. According to the link they should not be. I hope that helps clarify
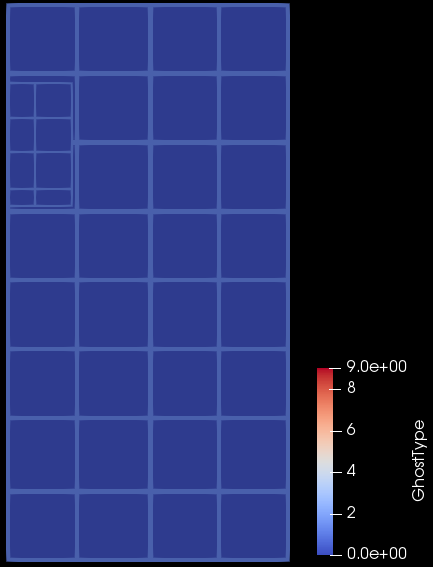
To visualize the ghost cells I add a copy of them named “GhostType” and color by these. I am expecting to see all zero in the rendering, but what I see is cells marked DUPLICATECELL are rendered.
here’s a dataset. data.tgz (84.0 KB)
Open it, set default number of levels to 10, apply, representation to surface, change scalars to GhostType
Hmmm. I see the issue. The XML reader computes its own blanking information overwriting he vtkGhostType array in the file. See vtkXMLUniformGridAMRReader.cxx : 463. If I copy the GhostType array to vtkGhostType using the programmable filter like below, it works:
I am guessing that the reader needs to preserve the input array and || the REFINEDCELL values that it computes. Alternatively, if the input data has proper ghost arrays, we could add a flag to turn off computing the blanking information. Which one do you think is the better way?
If the ghost arrays are in present it would be safe to skip computing the ghosts if one is reading the entire mesh. However, if you are reading some subset of the mesh then ghost arrays need to be recomputed.
What if in addition to refinement ratio and amr boxes (etc) the vtkOverlappingAMR dataset
captured the number of ghost cells? Then the reader could completely regenerate the ghost arrays as needed.
Good point. So recomputing the blanking is necessary. In terms of ghosts, don’t we have enough info already? The extents not covered by the amr box should be ghost, right? So that code could also generate DUPLICATECELL values, which I don’t believe it currently does.
yeah, you are right, you do have the info to calculate the number of ghosts cells. having the number of ghosts in top level member var would make writing filters slightly easier, but one could live without it. i have a slight preference for the member variable, but in the end probably doesn’t matter too much which way you go.
there might be some other metadata to think about including. such as periodic boundaries. useful for things like path line tracing and pincare plots. supporting a refinement ratio for each coordinate axis, a feature of amrex. I think image data supports that, but not sure how hard it would be. those are other somewhat related issues, thought I’d mention as I think this thread is pretty much resolved
The reason I’m asking about the eta for the fix is that I could not get your work around using the Python filter to work, I got errors about RequestData not being defined. I also tried the Python calculator, which seemed to work, but then the rendering disappeared after hitting apply. I’ve noticed that the data disappearing is characteristic of applying other filters, such as the extract level filter. After the data disappears by applying a filter such as the extract level filter I need to delete the entire pipeline and re open the files to get it to show up again. deleting the problematic filter doesn’t help. This behavior was the same for extract levels and the Python calculator. With all the bugs it’s been a challenge to generate a catalyst config script. It would be awesome to have a clean path to work with amr data and set up catalyst config script.
I am starting to take a look at the issue. Having said that, the rendering becoming dorked up is probably not related to anything here. There was a bug on master for quite a while due to some Qt OpenGL widget changes. If you were on master, you would run into that. As far as I can tell on my Mac, this is now fixed. I’d like to know more about the Python filter issue. The error you mentioned makes me thing that there is actually an error in the script - usually some sort of typographical error - which causes the parser to fail.
I don’t have an eta unfortunately. I have been very busy with other projects so I can do this only during my down time.
The programmable filter can be made to work by fixing the quotes when pasting the code. Because I didn’t quote that block, the quotes come as some fancy utf8 thing. Try this: