I am working with LES simulations that generate large data files. I am working on a cluster with OpenFoam and Paraview 5.13.1, running natively on the cluster. Paraview runs in parallel and also uses a GPU. The problem is that it takes a long time to load an Openfoam case, about 20 minutes for each Time Step with a Decompose Case.
So the first question is: In your opinion, what is the most efficient way to load the case: with an OpenFoam Recompose Case, a Decompose Case or converting the files to VTK format?
I think the bottleneck is the HDD’s but seeing the usage, they are not working at their maximum reading capacity, so please give me your opinions on what else it could be.
I’m working on it, but when I run pvserver or even pvbatch i can’t use the full power of the cluster even in on node.
I use both comands (mpirun or mpiexec), but neither uses all the processors I assigned, in fact I can only assign the number of available GPUs which are 3 per node and still it does not use them, it only uses 3 CPU processors
curious about this as my bottle neck is also paraview and clearly I think i am using it wrong somewhere. my case are decomposed into 8 processors, and in the visualization of the .foam file if i choose vtk coloring i get as brayan, 12 values, but my complete geometry is grey (i clipped in case that they were inside of the mesh but no the mesh is fully grey) i tried to use threshold to see but i could not select vtk block colors for this.
when I am running paraview i am simply calling $paraviewPath/paraview sim.foam and when using pvbatch same $paraviewPath/pvbatch sim.foam I am using the nightly version of paraview, the simulations were done in OpenFOAM ESI 2406 version (in case it matters).
I imagine that I am doing something wrong. Also when I open the sim.foam the terminal that runs paraview outputs
Brayan,
A few fundamental questions. Are you running in Parallel?
Run Help/ About/ Remote Connection? Does this say you have a remote server?
View/ Memory Inspector. How many processes/ ranks are you running? The memory inspector will show you memory footprint for each rank.
Lets not talk “processes” as the ParaView reader doesn’t care. How many files are in your dataset?
Franco,
You are running ParaView and pvbatch with a built in server, as opposed to a parallel cluster. Reading in serial is going to be slower than a parallel cluster.
Hello Walter and Mathieu, thank you for your help.
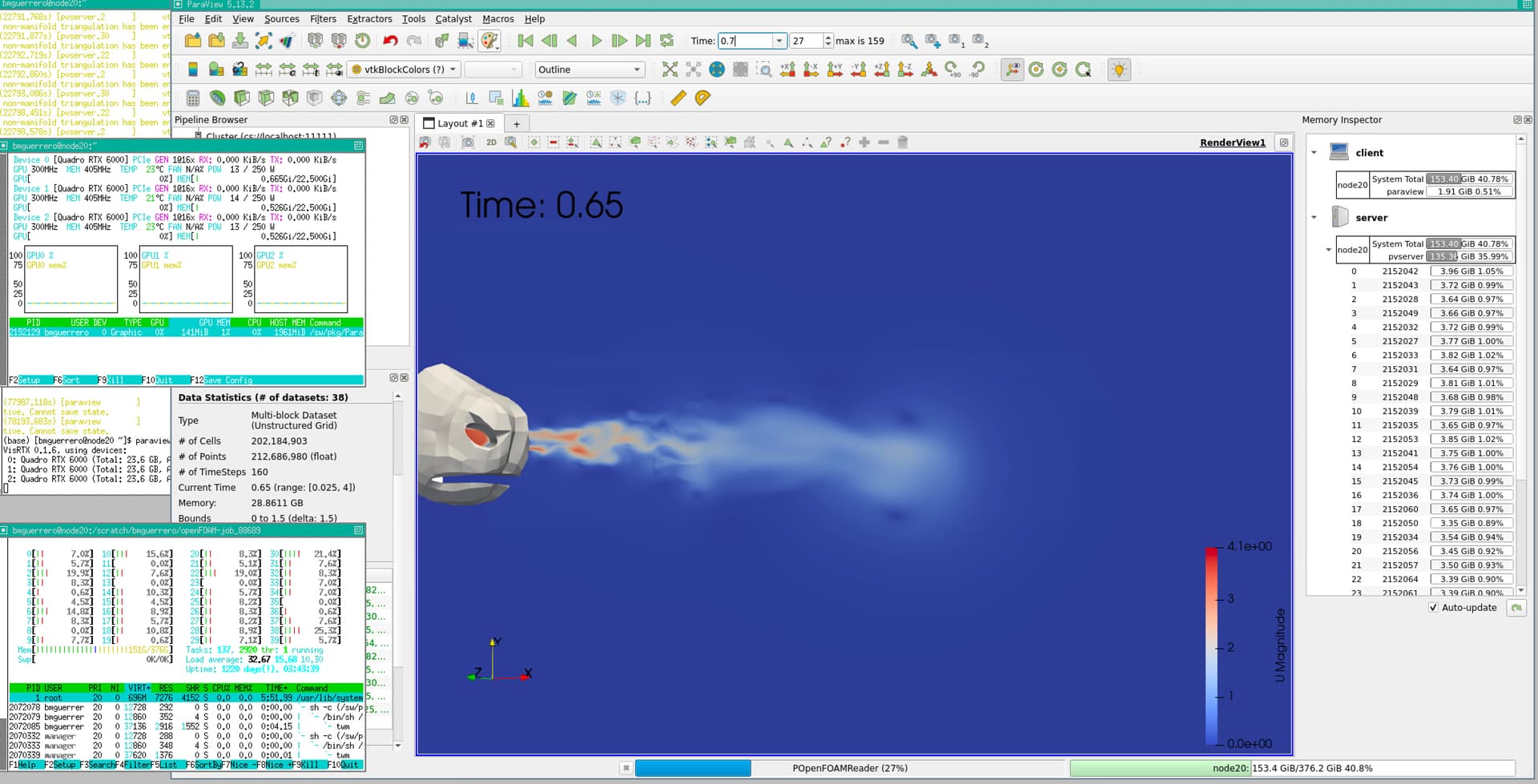
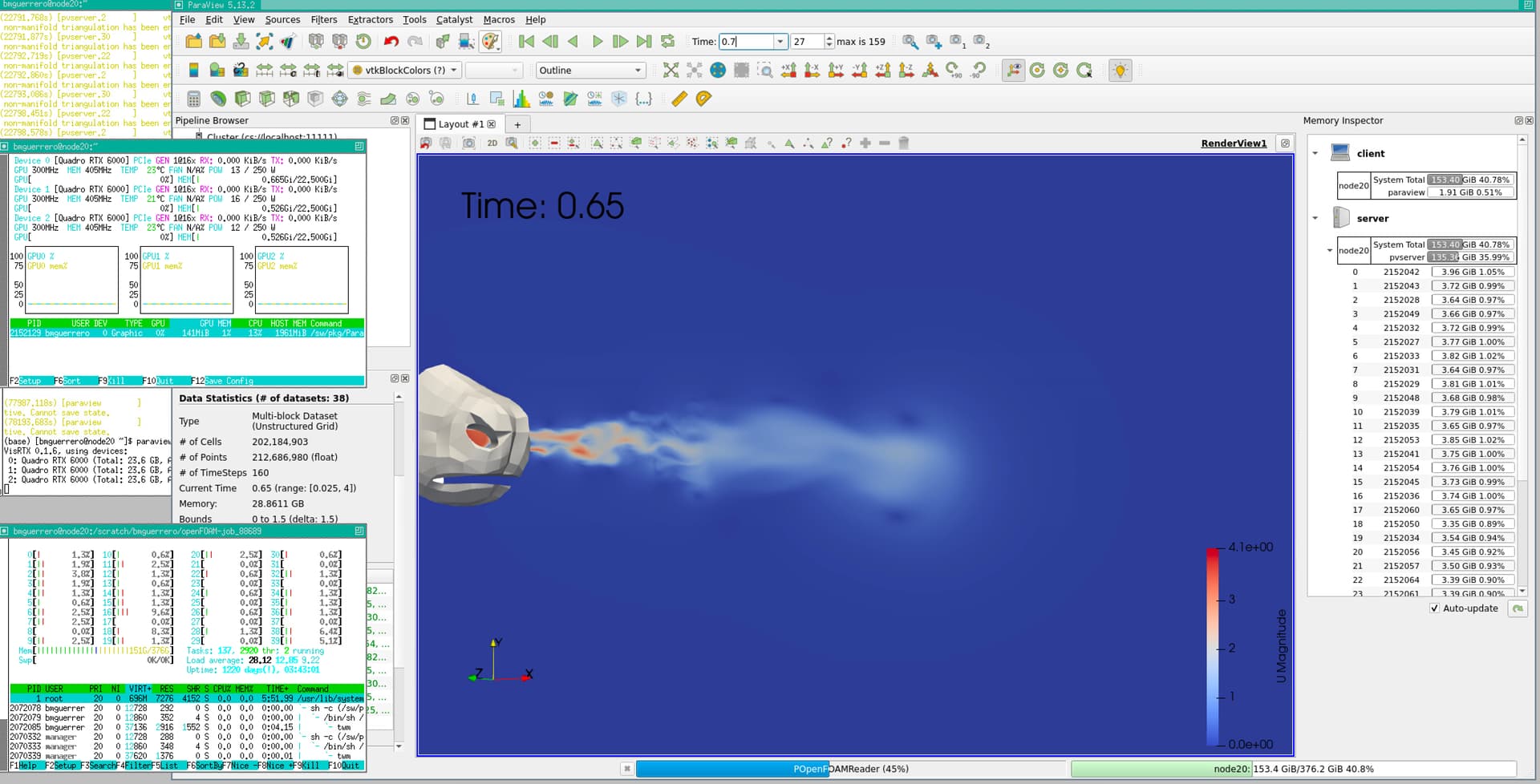
It seems that the cluster was not working correctly with some commands, Now i’m working on a pvserver started on a node with command: mpiexec -np 38 pvserver --mesa --mpi (I added --mpi) and then I connected to it on the same node launching Paraview with paraview --parallel. The load time has decreased substantially (about 5 min) and the node is fully utilized. I add a screenshot when the program is loading a time step.
I think it is a bit difficult to share my data because the folder for each processor is 11gb in size, the total size is about 4 tb.
Another thing I have noticed is that using mpiexec -np 180 pvbatch --mesa --mpi (again adding --mpi) with a Paraview non GUI build has allowed me to use more than one node to render images and graphics and this speeds up the process even more. Now I have been having problems saving states in .py format, after twice exporting in this format paraview does not save new states, it does not even create new files.