I am writing a Python plugin using the VTKPythonAlgorithmBase class. I am performing an operation across many blocks within an input MultiBlockDataSet. I also need this operation to be tolerant of being run in parallel.
The overall goal of this operation is that a user should be able to specify three node IDs (stored within the input dataset as a PointData array “NodeGID”), and the coordinates of those three nodes (points) should be returned. The RequestData method is excerpted below:
51 def RequestData(self, request, inInfo, outInfo):
52 print('')
53 print('&'*50)
54 #initialized input and output objects
55 input0 = self.GetInputDataObject(0, 0)
56 output = self.GetOutputDataObject(0)
57 #make output a copy of input to start
58 output.ShallowCopy(input0)
59 #iterate over MBDS
60 iterator1 = output.NewTreeIterator()
61 iterator1.VisitOnlyLeavesOn()
62 iterator1.SkipEmptyNodesOn()
63 iterator1.InitTraversal()
64 trav_count = 0
65 while not iterator1.IsDoneWithTraversal():
66 print('trav_count = {0}'.format(trav_count))
67 #get current object
68 block1 = iterator1.GetCurrentDataObject()
69 print(type(block1))
70 #if it's an UnstructuredGrid (which is should be, but this is just a check),
71 #then do everything else
72 if isinstance(block1, vtk.vtkUnstructuredGrid):
73 #get node IDs and convert to numpy array
74 ngid = block1.GetPointData().GetArray('NodeGID')
75 nids = vnp.vtk_to_numpy(ngid)
76 #find indices for nodes (if they exist)
77 ind1 = check_for_nid(nids, self.n1)
78 ind2 = check_for_nid(nids, self.n2)
79 ind3 = check_for_nid(nids, self.n3)
80 #log successful finds
81 if ind1 >= 0:
82 self.found_n1 = True
83 self.n1_tuple = block1.GetPoint(ind1)
84 if ind2 >= 0:
85 self.found_n2 = True
86 self.n2_tuple = block1.GetPoint(ind2)
87 if ind3 >= 0:
88 self.found_n3 = True
89 self.n3_tuple = block1.GetPoint(ind3)
90 trav_count += 1
91 iterator1.GoToNextItem()
92 print('')
93 print(self.found_n1, self.n1, self.n1_tuple)
94 print(self.found_n2, self.n2, self.n2_tuple)
95 print(self.found_n3, self.n3, self.n3_tuple)
When I run this in parallel using 2 CPUs, it appears that the operation is being parallelized by blocks. See a screen capture of the output from Paraview in my terminal below:
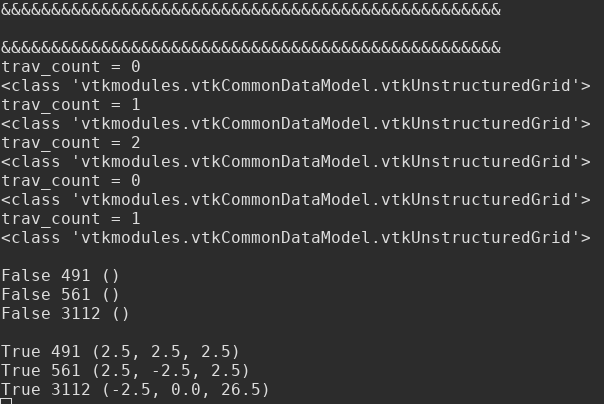
There are five UnstructuredGrid blocks in this dataset, and based on the printout of the trav_count counter, three blocks are being handled by one CPU, and two blocks on the other. However, only one of these CPUs is processing the block that actually contains the three nodes of interest. This can be seen in the last two chunks of output. One of the CPUs returns all Falses and empty tuples. The other returns Trues and the correct coordinates.
So my question is, how do I merge these results back together before using those coordinates to do further work (e.g. apply a Clip operator)?. Based on my current understanding, everything within the plugin class will remain parallelized up until completion, so the results of the multiple CPUs never communicate with one another. This becomes a huge problem if one CPU finds n1, and the other CPU finds n2 and n3.