When we run pvserver in parallel using mpi, does the memory of each node get shared?
I have a 2 node allocation on my HPC where each node is able to support 64GB of memory and has 16 cores + 1 p100 gpu, but I’ve found that even though I start the pvservers with ./mpiexec -np 32 ./pvserver --displays --egl-device-index=0 from the folder where I downloaded the mpi enabled paraview the servers will crash as soon as I pass the 64GB memory limit. I would have expected that by running in parallel with two nodes I’d be aggregating the two nodes memory and therefore have 128GB of memory, but perhaps this is only possible with additional configuration? Thanks for helping me wrap my head around this.
I’m not sure where you see this information of memory usage but ParaView usually report memory usage by nodes. To me it looks like you are using more than 64GB memory on a specific node.
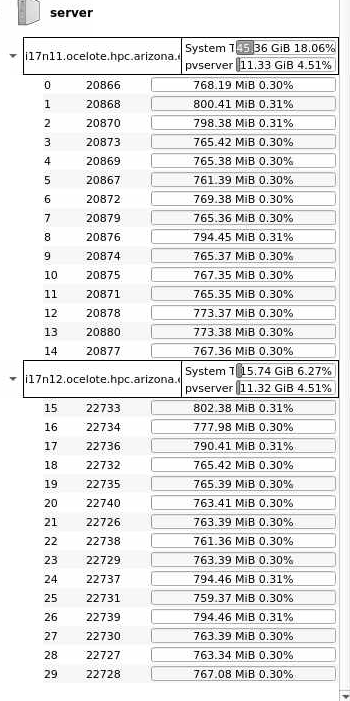
The way to see how memory is allocated in ParaView is using the View/ Memory Inspector. If you use only one or two nodes, it will open up and show you memory usage by core/rank/process.
A super easy way to “create” data to see memory use is using the Sources/ Wavelet. Just keep making it bigger, and you can see it spread (hopefully) across cores and nodes.
At least on all of the clusters I work with, memory is shared between cores/ranks from the node. Thus, you have 64 GByte of memory, each rank will pull from this pool. Note that when it says “percent usage” or whatever per rank, this is a lie. Each ParaView (pvserver) process thinks it owns the whole node. But the usage for the node will be correct (see next bullet).
ParaView memory inspector shows you the low water mark of memory usage. I believe that is because rendering each timestep will grab additional memory, use said memory, return said memory, and the memory inspector never sees this. (The memory inspector, I believe, does a “free” call to the OS.) The takeaway is that if you are using more than 50% of memory things may be getting touchy, above 70% is definitely working without a net.
ParaView readers generally don’t spread a single file between ranks. Are you trying to open a single flie? Don’t do this - open the original spread data.
Hope that helps,
Alan
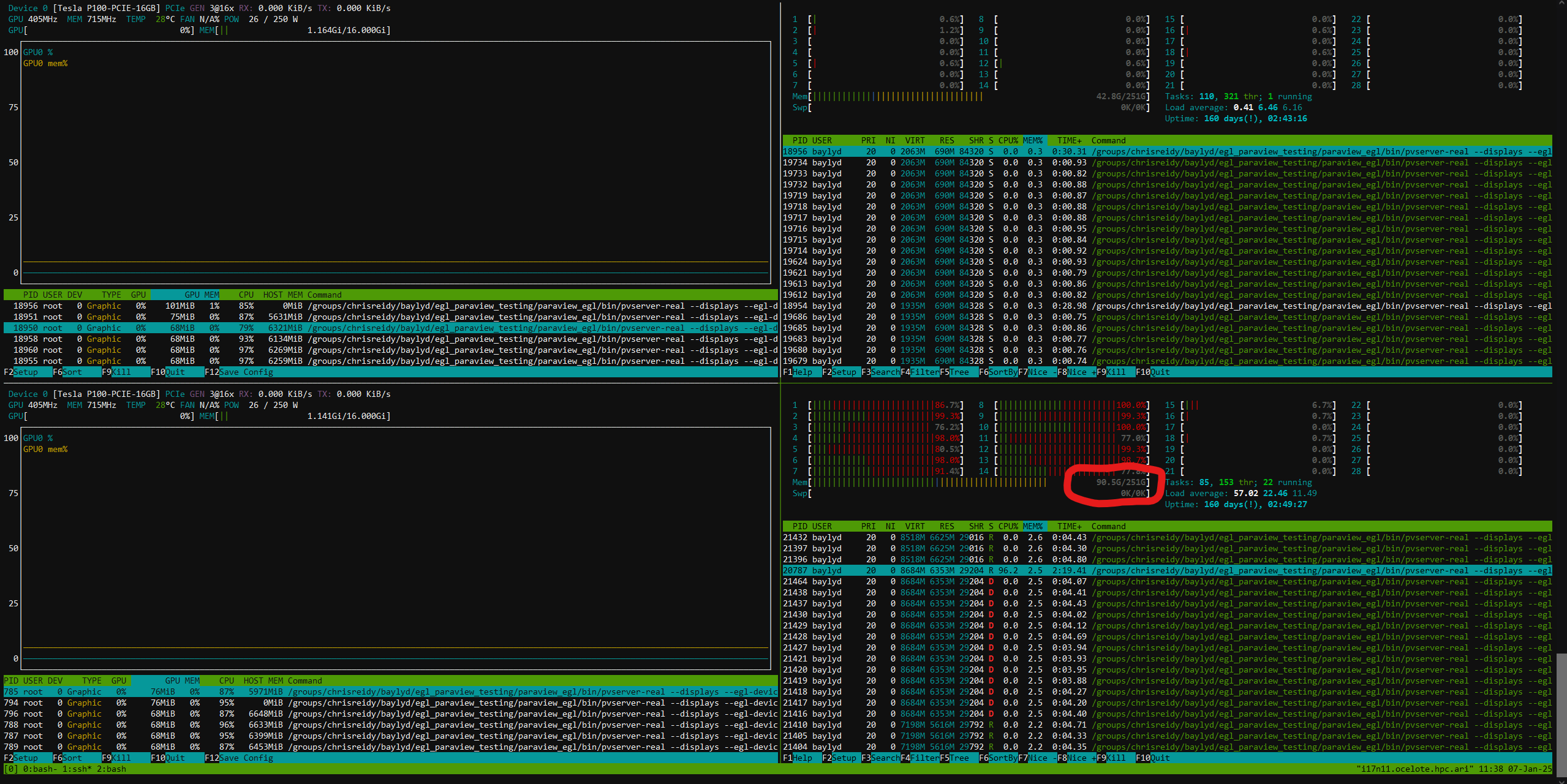
I was running nvtop on the two nodes so i could watch gpu utilization and cpu memory and you’re totally right that the node that had more mpi processes on it was the specific node that ran out of memory. I think I naively thought that it would balance the memory between the two nodes, but perhaps because the processes aren’t balanced between them, the memory wasn’t either?
For the clusters I work on, and I expect all clusters/ supercomputers, memory is not shared between nodes. You don’t want memory shared between nodes - your cluster would freeze up with passing memory between nodes on the fabric (I think that’s the term).
“” in response to the first of your replies""
that’s a great tip, I’ll use this trick when I’m trying to troubleshoot each configuration that I test out.
also that’s very helpful information about the ratios of memory used and when I should consider myself “without a net” haha.
for the last point, I’m opening a single file that I’ve modified so that all the 2d simulation outputs are stacked together into a volume. The opening and basic volumetric visualization I’m doing doesn’t put me in OOM territory. When I try to perform some scaling operations I see things crash. With this in mind, is there still a way to “spread” this single file of data as you mention?
It looks like RedistributeDataSet is mostly what I need, but when I tested it out I ran myself out of memory in the process haha. I’m in a good enough position to try working on this myself, but I wanted to just ask briefly a related question.
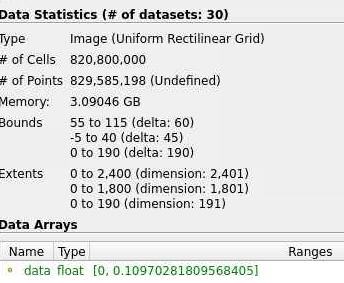
My starting file is only 3gb, and these dimensions
the memory used for this looks something like this when I use the memory inspector (great to know about this now ty!)
You open the file on one node: node 1: 60Gb, node 2,3: 0Gb
You redistribute the data, which means the data is being copied: node 1: 60+20=80Gb, node 2,3: 20GB
If you are able to do this, you should then save the distributed data in a file format that supports it (eg: .pvtu), and then close ParaView, reopen it, and open the distributed file, this will reduce your RAM usage.
TBH, you should use a distributed file format in the first place
Ah, that makes total sense. I found some more information about the distributed file type and I’ll start learning more about that. Thanks for all your help!