Those who scanned through the Scientific Visualization in 2022 blog may have noticed that there are some exciting new ways in which we are trying to evolve the ParaView ecosystem. One of those directions is what we’ve been calling ParaView Async. This started as a DOE Phase I SBIR in 2020. We experimented with some new ways of thinking about pipeline execution (especially data processing and rendering pipelines) and remote processing APIs to improve responsiveness of the whole application. If ParaView is to continue to be one of the major scientific data analysis and visualization tools, it needs to provide the same user experience that users come to expect from applications, desktop and web alike.
In Phase I we developed a prototype platform based on Thallium and then developed applications to compare the same workflow side-by-side with current ParaView platform and this new prototype.
Here’s an interactive streamline placement app based on ParaView.
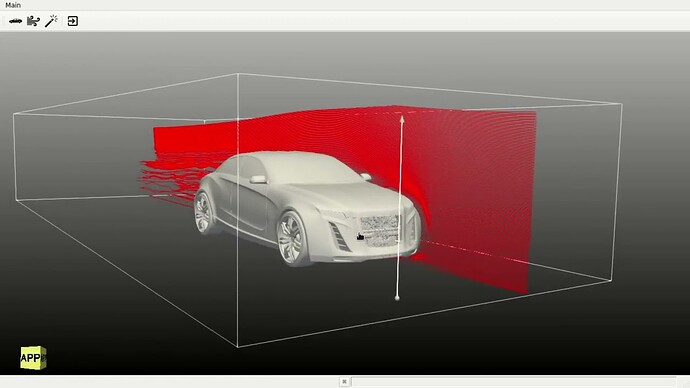
Versus the same app based on the new prototype platform.
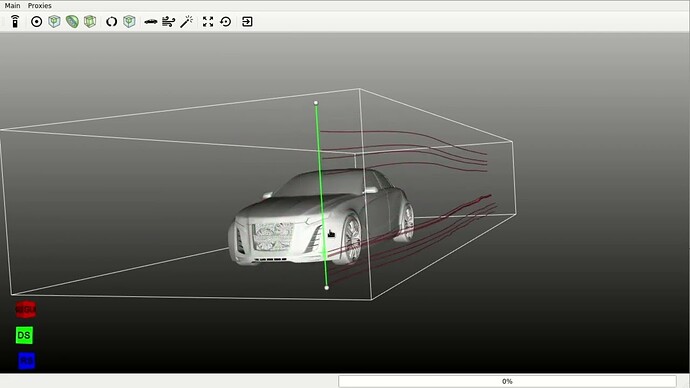
And here’s a similar comparison but this time in a web-app.
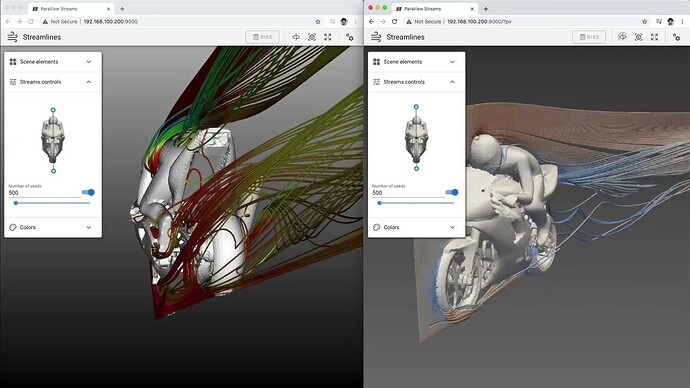
Based on these results, we secured Phase II funding to take these ideas to production.
Since late-2021, we’ve been developing this next-generation ParaView platform. One of the most difficult challenges so far has been to decide how ambitious we should get. We can easily think of this as a brand new platform and totally rework how ParaView fundamentally operates. However, that risked alienating the entire existing ParaView community making it really hard to port existing applications and workflows. So we decided to take a more tame (and sane) approach. We keep the basic building blocks the same i.e. data-server, render-server, proxies, etc. but then update APIs and behaviors as needed to support the asynchronous processing model. We are less than half way through this project and we are at a point where we can share the developments with the community and get feedback.
For ParaView users, here’s a short video that demonstrates how this next generation ParaView operates. The application largely looks the same. The key difference is what happens when a filter is busy executing.
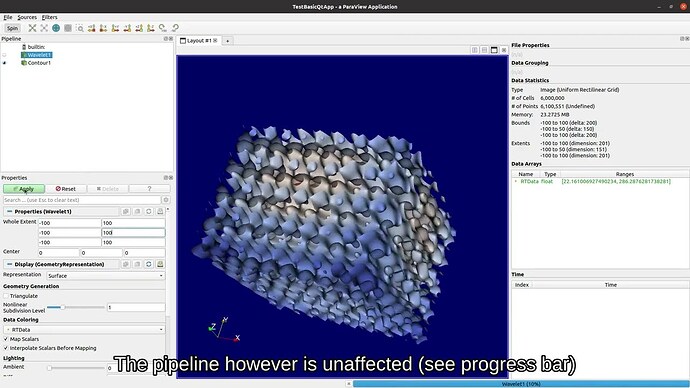
Key Design Components
For those who’re familiar with the intrinsics of ParaView, let’s now get into a little more detail. The core ideas that are driving this are fairly simple:
Concurrent pipelines: Currently, data processing and rendering is a sequential pipeline. Whenever a filter is busy executing, for example, no rendering can happen. We split this dependency. Instead, we enable concurrent data processing and rendering pipelines. Thus, even if a filter is busy processing, the scene is interactive and usable and can render new images. It follows that the rendering can continue to render images on its own too – supporting use cases like progressive rendering out-of-box.
Asynchronous APIs: In ParaView, all pipeline setup and management (remote or local) happens via Proxies (vtkSMProxy and subclasses). The proxy API provides several methods that can potentially block. For example, consider a client-server setup where the client is connected to a remote server and we have created a proxy for a reader. The client triggers a read by calling the UpdatePipeline method. While the server is busy reading the file, the client really is not doing anything. It should be interactive. However, the UpdatePipeline call notifies some panel that data may have changed which means that panel will attempt to get information about the updated data – which causes the client to block until the server is free to respond back with the meta-data. Long story short, we have APIs that can potentially block and it’s easy for the client to make those API calls since they are pretty much required to any non-trivial pipeline. By removing all such APIs and providing asynchronous alternatives, we can keep the client interactive.
Interruptible pipelines: Keeping the application responsive while some filter is executing, for example, means that the user can make changes to the filter so that whatever the filter was executing on is no longer relevant. In that case, we should interrupt the filter to avoid wasting compute cycles and more importantly the user’s time. Thus interruptibility becomes a core requirement of this new approach.
These are the key principles. Now let’s see how that affects the implementation in some detail in the next section.
Implementation Details
Services: Concurrent pipelines, asynchronous APIs, etc. naturally alludes to a multithreaded architecture especially since requiring multi-process setup is not an option – we want to continue to support the “builtin” mode. We are working in a largely thread-unaware VTK world; VTK filters, pipelines etc are by no means thread safe. So, instead, we adopt a model where the data processing and rendering pipelines are executing on different threads, but each pipeline itself is only executing on a single thread. We’re not talking about a filter itself using multiple threads internally to process the data, that is orthogonal to this discussion. To support this, we use services. We define a service as something that can respond to messages coming from another thread (or process) and then handle that request on a unique thread. Thus, within a service everything is sequential but multiple services can execute concurrently to one another. There’s more nuance to this, but we can ignore that for now. What we have traditionally referred to as “data server” and “render server” in the ParaView architecture can now be simply thought of as data-service and render-service. Even in builtin mode, these services now exist and are executing on separate threads concurrently with one another. When the data-service has prepared data for rendering, it dispatches that to the render-service which then renders it and delivers results to the client. While data-service is busy, the client can still send requests and receive updates from the render-service since it’s executing on a separate thread than the data-service.
Side note: while the ParaView application will only rely on these two services, there’s nothing stopping one from building custom applications that use more services to enable even more concurrent processing. For example, it’s easily conceivable that we have a separate I/O service to avoid I/O from clogging up the data processing pipelines.
The services infrastructure is developed as a VTK module. An abstract ParaView::ServicesCore module defines all the API and mechanisms to communicate with services, while a ParaView::ServicesThallium module supports the services API using Thallium. Any communication API provided by the services is by design non-blocking.
ServerManager: The ServerManager, together with proxies, proxy-manager, etc., is now built on top of the services module. Since the communication APIs provided by the Services module are all non-blocking, the ServerManager APIs too show similar changes. ServerManager itself, however, is not thread-safe. That is, one is not expected to use the proxy API on different threads. This is not too crazy. Since ServerManager is a client API used by the UI, the ServerManager API is only expected to be used by the UI’s main thread. This restriction actually makes things much easier on developers. Most of the ParaView client code doesn’t need to worry about multi-threading. There are some exceptions of course, but we can leave those for another day.
So now, when you create a proxy, its VTK-object will be created on the target services which are either on different threads or different processes. The core model is not much different than how it was in canonical ParaView, just the ordering of actions changes. For example, previously when you created a reader proxy, you could rely on its information properties being up-to-date so that you can offer the user which arrays are available for selection. This is no longer feasible because the data-service might be busy when the user creates the reader which means it can’t respond to the array selection information immediately. One will just have to wait till when that information becomes available to set it.
There are other cleanups here too. ClientServer wrapping is dead. Instead of wrapping VTK for a CS script, we simply wrap it to support lightweight reflection with getter and setters. This helps us get rid of all the vtkSI* classes and thus avoids that complexity.
While algorithm proxies are not impacted too much, views and representations have to be totally reworked. The new design has to support the complete decoupling between data processing and rendering sub-pipelines within representations. The new design, if you asked me, is much simpler and avoids the complexity we had with composite-representations, but things are still settling down here, so it’s better to discuss this in future posts.
One thing to note is that there’s no ClientSideObject anymore. You cannot ask a proxy for its VTK object even in builtin mode. This is because even in builtin mode, that VTK object is on a service which exists in a separate thread, thus it’d be unsafe to access any arbitrary VTK object for a proxy in the application’s thread.
GUI: Since large parts of the ServerManager API are the same or only changed a little, it’s not too hard to get things going. We have already got pqProxyWidget – the main class that manages generation of Qt panels for proxies – working with several custom widgets. Things like 3D widgets and other widgets that do non-standard things still need to be ported over. Components related to views and representations are the ones that are most impacted, of course, and will continue to be updated as we continue to make progress.
Wrapping up
There’s a lot more to discuss here. We haven’t described how distributed services work, or how Python scripting will work. Those are discussions in their own right and we’ll have follow on discussions on those. The goal of this post is to get the conversation started and lay the ground work for those follow-on discussion. Here’s a video demonstrating progressive ray tracing using OSPray working under this new platform.