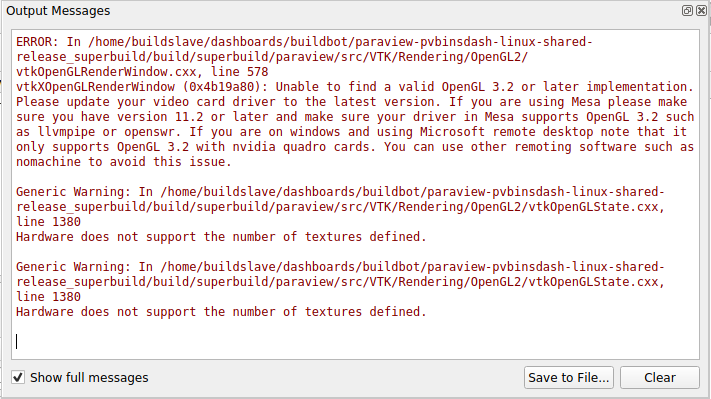
I am getting an error message every time I try and load files created in openFoam which uses the sprayFoam solver. The error is:
"ERROR: In /home/ubuntu/OpenFOAM/ThirdParty-dev/ParaView-5.4.0/VTK/IO/Geometry/vtkOpenFOAMReader.cxx, line 8285 vtkOpenFOAMReaderPrivate (0x558b15bd67f0): Error reading line 20 of /home/calvin/OpenFOAM/calvin-v1906/run/NozzlePipe3DCase/1e-05/lagrangian/sprayCloud/positions: Expected punctuation token ')', found 0"
The error seems to be with paraview reading the “positions” folder in the results. Does anyone know why this error is occurring and how I could fix it?
I am getting the same error with 5.8 and 5.7 on windows. Is there a work around that anyone knows off?
Solver used was Openfoam7, I might just have to foamToVTK it.
The positions file contains tuples of (x,y,z, cellId). This file is generally ignored by OpenFOAM (in favour of the coordinates file), but is readable by ParaView. The format is consistent with what older versions of OpenFOAM generated.
The coordinates file contains the barycentric coordinates. This is used for OpenFOAM restarts but not by ParaView.
The positions file was changed to contain the barycentric coordinates (identical contents to the openfoam.comcoordinates file). Cannot be read by ParaView.
It is probably not realistic to expect support for the openfoam.orgpositions file. This would require shadowing the volume mesh in order to define the cells, additional tet decomposition of the volume cells, additional barycentric calculations to determine the corresponding x,y,z positions.
Available options, in any order of preference:
use the openfoam.com version that generates a positions file that can be read by ParaView.
use foamToVTK or foamToEnsight to convert the lagrangian fields only.
Perhaps too much detail in the explanation, but essentially the original positions file (and the one that openfoam.com continues to generate), is fully supported by ParaView. The problem is that the .org version now populates that same filename with completely different contents (the barycentric coordinates) in a format that is non-trivial to support. Perhaps a KitWare guy might wish to weigh in with comments about how much development time and memory overhead would be involved to support barycentric coordinates (implementing all of the aforementioned steps). I see this as an upstream problem, not a ParaView problem.
I now fully understand the difference. Remember both openfoam versions have their own readers. The org version is on their Github and built into their version of paraFoam. It is not then just a matter of adding it into paraview?
The openfoam.com version is also readily available as a module, but adding any of them is not a solution since they are built using OpenFOAM components (in addition to being serial-only). We’ll ignore licensing questions (GPL vs BSD) and concentrate on the technical.
In the OpenFOAM reader plugins, the OpenFOAM infrastructure is used to read in mesh, lagrangian etc and then a conversion is done to transcribe them into VTK formats. This means that the volume mesh exists at least twice in memory (first as an OpenFOAM mesh, second as a VTK mesh), which gives them more overhead than the native ParaView/VTK reader. The handling of lagrangian particles in those reader plugins uses that OpenFOAM infrastructure, which means that they can readily convert to x,y,z positions (since they always have the corresponding volume mesh in OpenFOAM format).
If you want to replicate this in the native reader, you are back to the entire business of always reading in a volume mesh, performing the decomposition etc. This is quite a lot of coding and overhead to solve the problem of the .org version only.
You could try with OpenFOAM-1912, which will be largely compatible with the .org version. If you have an existing lagrangian simulation, you can simply rename the positions files to coordinates and perform a restart.
Without a restart, you could rename positions to coordinates before using foamFormatConvert, which should generate the positions file in the known format.
However, the fastest will still be to use foamToVTK. In the OpenFOAM-1912, you would use
$ foamToVTK -no-boundary -no-internal
# or
$ mpirun -np N foamToVTK -no-boundary -no-internal -parallel
@Quefrency : For the Kiware side of things, we do not integrate these different readers for different reasons :
We can’t “just” integrate it, we would have to clean, reorganize and even, as @olesenm stated, redesign part of it to make it more VTK-like
These readers depends on OpenFOAM, we can’t add OpenFOAM as a dependency, even in the superbuild, for licensing reasons, so that would be a big design changes on these readers.
This work would cost money and ressources, and so far, nobody as been willing to pay/do it
Once integrated, it become our responsibility to make sure it works with all type of dataset, new versions of OpenFOAM, etc.
The current reader is already complex enough and has it’s own oddities. We are incrementally improving it though.
However, with the existence of project like paraview-plugin-builder, It would probably be possible, for a third-party to produce OpenFOAM readers plugin that can be loaded in the ParaView release.
Thanks for the detail explanation of the different readers. It is very help for me to decide which version to use going forward.
I think I will have to move over to the .com version to have better compatibility with paraview.
I think I will open the .org results with parafoam and save the data through parafoam to vtk, to have the data in the most up-to-date vtk format. From the best of my knowledge openfoam7 is still using the legacy vtk format in foamToVTk while .com has updated the foamToVTK utility.
In short, and I agree with @olesenm, that I show get any openfoam data into VTK for the best user experience with paraview.
@mwestphal that for your explanation as well, it is much appreciated.
The openfoam.com foamToVTK still supports the legacy format (with the -legacy option), but people usually use the newer formats. It can generate multi-block vtm, vtu, vtp with accompanying time-series (json) files. The XML formats are the inline versions (ascii or base64 encoded binary). No support for using internal file compression or the appended formats (raw binary or base64) since this did not fit well with how the files are being generated internally.