I recently had the opportunity to use ParaView for setting up a CFD visualization: exploring what works, what doesn’t and deciding how to generate the best possible visuals (ParaView is brilliant, btw!). Here’s a proposal to help users manage state and other artifacts for such exploratory use-cases of ParaView to generate quality visualizations.
Use-case
To understand the motivation and design for this feature, let’s consider this use-case.
I am ParaView user who is setting up visualizations for an upcoming conference, say SuperComputing 2024.
For such a use-case, key things to note:
- I will have a collection of datasets that I want to generate the visuals from. These datasets can change, over time, but the main point is that the input data is available somewhere and will continue to be available at that location throughout the Workspace.
- I will be using ParaView to generate various artifacts. Artifacts are not just images or videos, but also datasets or exported files. It’s conceivable that I will open some of these artifacts in other VFX tools to generate final visuals.
To support such use-cases, let’s introduce a new concept of Workspace.
Workspace: Basics
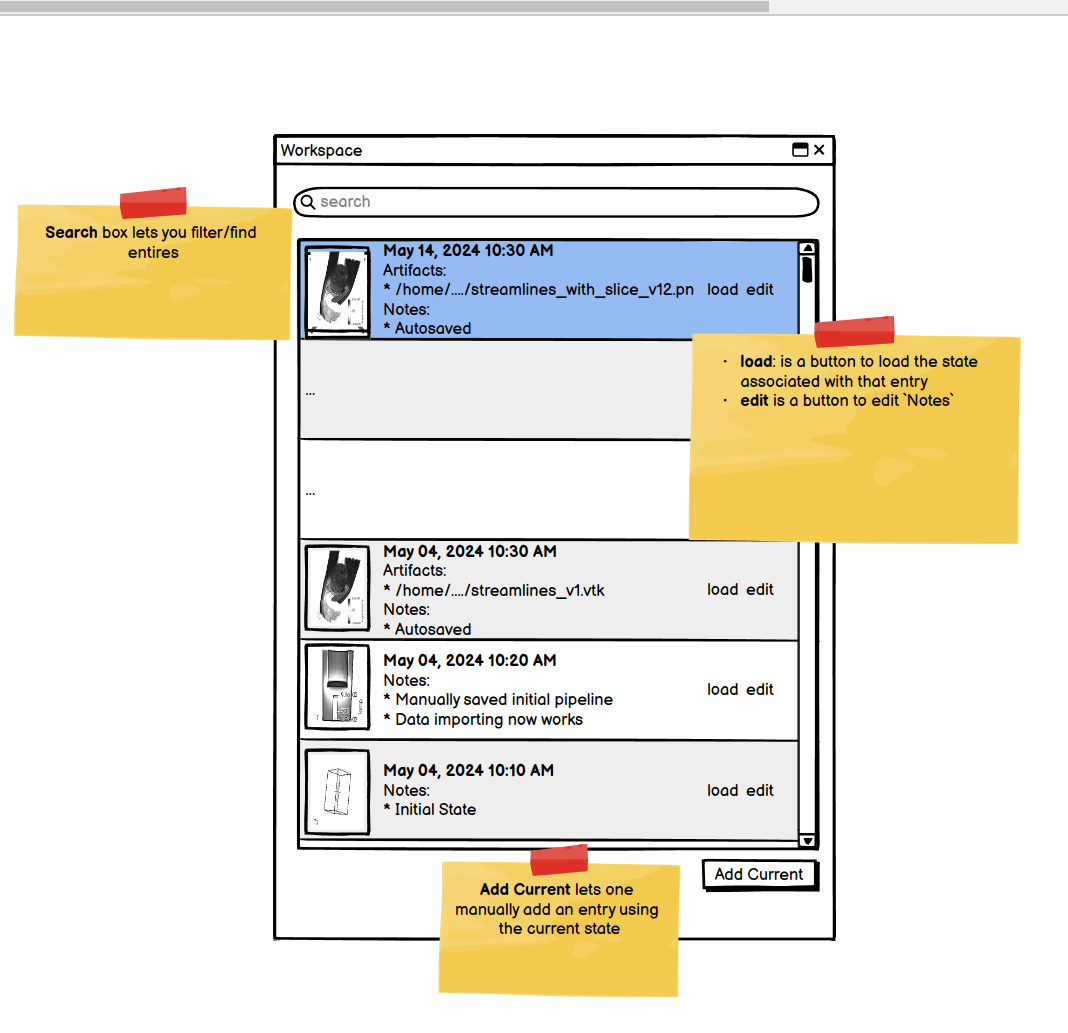
One can think of Workspace as a mechanism to log and collect ParaView state files with annotations. Each entry in the log is a complete ParaView state file together with a thumbnail of the renderings in that state and any other annotations. Workspace entries can be added manually by the user. ParaView will automatically add entries any time the user generates an artifact such as save a dataset, screenshot, or even a state file. In such cases, information about the artifact, such as the path to the file that was generated, the data producer it was generated from (if applicable), etc. is added as annotations to the entry along with any custom annotations the user wants to add.
Workspace: Walkthrough
Let’s see how this helps us with the use-case we began this post with. I am given a dataset, say the OpenFOAM motorbike and now I am tasked with generating interesting “artifacts” that I can bring into Omniverse to generate high quality videos for SC – a totally made up but very realistic use-case. Here’s what my workflow may look like:
- I open ParaView and start a new Workspace (using the File > New Workspace menu option). ParaView will ask me for a location where to save this new Workspace say BikeSC2024. This will create an empty folder under which the Workspace’s log (we’ll talk about the format for this later) and other byproducts are stored.
- When a new Workspace is started, the initial state is captured as the base. Thus, if I started my Workspace half way through my exploration, my current state will be base. The initial entry also includes all information about extensions loaded. Thus, when I open a Workspace those extensions can be automatically loaded too.
- Besides the initial state, the Workspace also always includes the latest state: let’s call it the session state. It’s saved right before I hit Apply or may other major changes that may cause ParaView to crash or quit. Thus, I can always get back to the point where I was in my Workspace before the crash or exit.
- Now I start playing with the dataset. I generate a set of streamlines that I think are good and decide to save those to a
.vtkfile so I can import them in Omniverse to integrate with rest of the scene elements. I call this filestreamlines_1.vtk. As soon as a I do that, ParaView automatically logs the current state along with the full path to the file I saved out as a entry in the active Workspace. If I go to the “Workspace Explorer” panel, I see an try for the current state, a thumbnail for that current screen shot along with the deatils for the file generated. I can add custom text to this entry too to add some details that I can find useful later on. - I keep playing with the dataset and generate several different versions of streamlines saving them out as different files, each time an entry is automatically logged in the Workspace.
- When I am done, I close the Workspace (or quit ParaView) and pass off the various streamlines to the VFX team.
A few days go by and the VFX team comes back saying they like streamlines_10.vtk and streamlines_15.vtk but we need to regenerate them since we need to compute voriticity and save that to the data as well. And this is where the full power of a Workspace can be unleashed!
- I start ParaView, and open the BikeSC2024. Immediately, ParaView is at the state I was in when I quit ParaView the last time I was playing with this Workspace. All extensions I had loaded then as also loaded so I don’t have to remember to load those.
- I go the Workspace Explorer and search for entries where the 2 files of interest where generated. Clicking on any one of them will take ParaView that that state precisely. Say, I pick state for streamlines_10.vtk. I modify the pipeline a but and generate new file
streamlines_10_v2.vtk. Again, a new entry is automatically logged. I add annotation text to that entry to say “Adding vorticity”, so I know what was my intent here. I repeat the same as many times needed and I am done!
One can imagine what this scenario would look like if there was no such thing as a Workspace. Firstly, I’d never remember how I generated any of the streamlines_*.vtk. Thus,I’d have to start from scratch. If I was wiser and I had saved state files, I’d have to manually track which state file was used for which dataset etc. The beauty with a Workspace is that all of this is automatically captured. Even if I have to go back and generate new versions of the artifacts a year from now, I easily can since I don’t have to remember the file naming conventions I used.
Miscellaneous comments
- This is similar to what features we had in the past like Lookmarks, VisTrails, etc. but is more automatic than lookmarks and simpler than VisTrails. VisTrails automatically captured all state changes which lead to both instability and excessive verbosity. Workspace, on the other hand only automatically captures entries where artifacts are generated. Of course, user can always manually log the current state to an entry using some UI element,
- I believe this also addresses the original use-cases for which this feature was designed, but goes much further than what we did there.
- For the Workspace file format, we can easily have some XML but a preferred way perhaps is to use a standard schema e.g. PROV-Overview.
- Note, a Workspace doesn’t actually store the datasets generated or input datasets for that matter. Users can of course save all the artifacts they generate in the same folder as the Workspace, but that’s irrelevant.
- When capturing state when an artifacts is generated, we could capture all details about how the artifact was generated e.g. the writer parameters etc. I, however, think that complexity is unnecessary. Keeping things simple is more important at this point.
- In theory, then entries can be a DAG thus tracking the provenance more elaborately. For the UI, however, sticking with a simple listing for the log entires is perhaps better…again, preferring simplicity over complexity.
edit 2024/05/28: changed name of the feature from Campaign to Workspace