I’m using pvbatch to post-process DNS data and although calculations scripted in Python are quite fast, saving the data requires a prohibitively large amount of time.
Here is the function used to save the data:
SaveData(’/path/file.pvd’, proxy=activeSource )
It’s also taking a long time to save them when launching pvbatch in parallel.
Is there a more time-efficient way to save such large datasets?
Calculation of various quantities (on unstructured grid with around 50e6 points and circa 400 time instances)
-* Gaussian filtering
Temporal statistics
-* Slicing
Saving data (on unstructured grid, structured grid or slice) --> sticking point = very high amount of time (days)
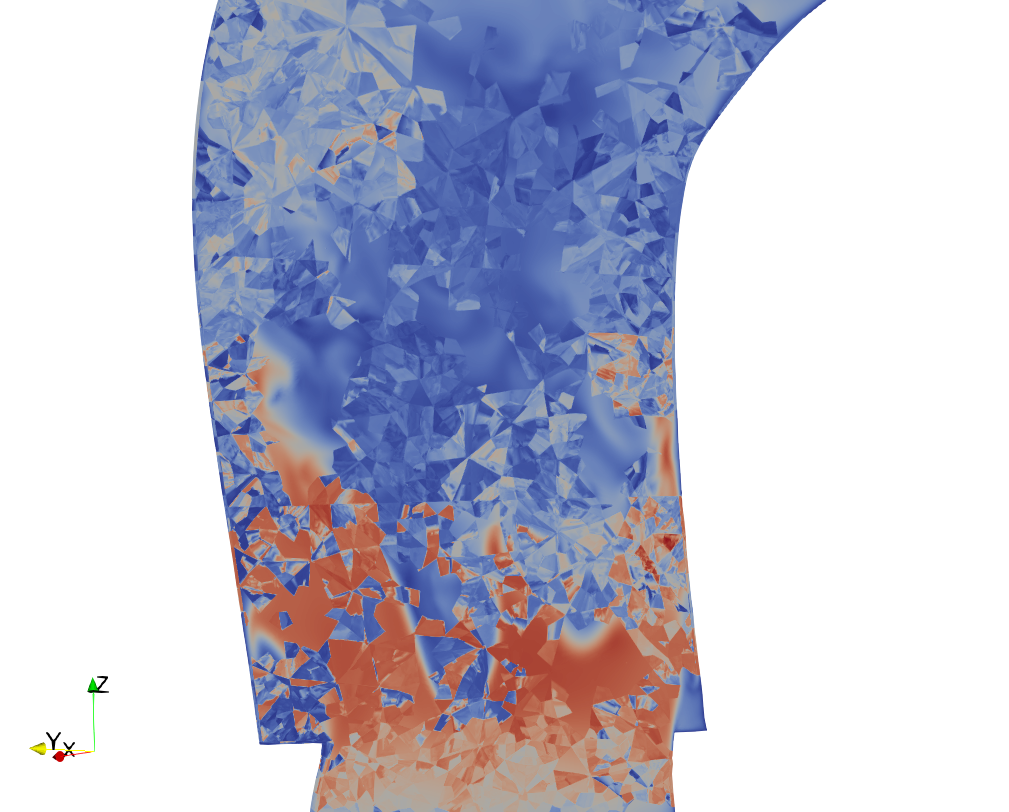
I also noticed that the reader for NEK5000 fields isn’t stable. It seems that sometimes (for several time instants) the indexing of the points isn’t done correctly (see attached figure).
Using legacy VTK and Exodus formats does not speed the process up.
Furthermore, when I apply the temporal statistics filter to the unfiltered DNS fields, I obtain an averaged field with misplaced points like the ones in the figure previously sent.
Hi Pascal,
I have a quick comment. I believe the Nek5000 reader for Paraview depends on the VisIt reader. I know that in VisIt the element numbering can be messed up because it bases the mesh on the first file in your batch, i.e. if you have binary files fld0.f%05d, the reader takes the mesh from file fld0.f00001. If you obtained the files from different runs, the meshes might be inconsistent. At least this is an issue I’ve ran into quite a few times, specially when I create new files from a post-processing step, for example, when computing vorticity from dumped velocity data. In that case it is useful to dump out grid data (ifxyo = .true. in Nek5000) for at least the first file of the sequence. Just keep this in mind.