I have conundrum; figured I’d solicit feedback publicly.
Here’s the context:
I am working on a new Extract Block filter that extracts blocks using names/paths instead of some internal ids (as it currently does) which are overly sensitive to the data hierarchy.
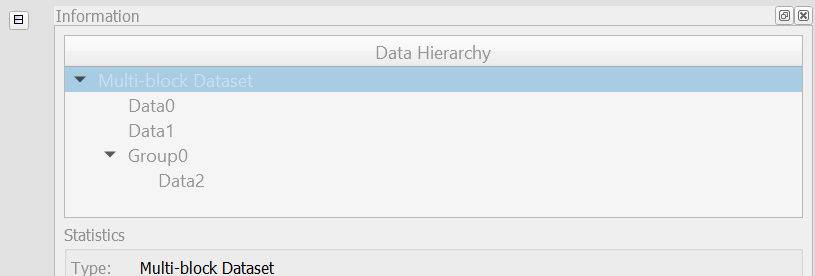
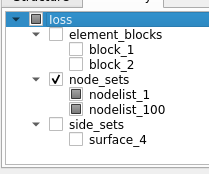
Consider the following hierarchy from a Ioss/Exodus reader as an example:

Here, in this new ExtractBlock filter, to extract nodelist_1, for example, one can specify the full-path, /Ioss/node_sets/nodelist_1 or a shorter version, //nodelist_1. Multiple such paths may be specified to select multiple nodes. Thus, to select both the nodelists, one can add two paths as follows: [//nodelist_1, //nodelist_2], or simply select the parent node using a single path //node_sets.
While for this file, the result will be identical no matter how the 2 nodelists are selected, the result may be totally different on a different file with differently named nodelists or different number of nodelists. Specifying paths as [//nodelist_1, //nodelist_2] will ensure that no matter what the file, only the blocks for nodelists named nodelist_1 and nodelist_2 will be extracted. While using the //node_sets as the path results in all blocks under the node_sets being extracted no matter their names or count.
Now, the problem: how to make it clear in the UI which of the two ways has the user made the selection, i.e. has the user chosen the two nodelists explicitly or has the user chosen all nodelists by checking node_sets node instead?
Option 1: The standard behavior for tree-views is that for any node, if all children are checked, then the parent node is rendered as checked as well, if none are checked it’s rendered as unchecked and if some are checked and some are unchecked, it’s rendered as partially-checked. This is what ParaView does currently. This is definitely a no-go since the widgets appear exactly the same no matter which of the aforementioned two ways the nodelists were selected.
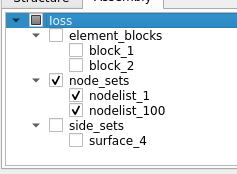
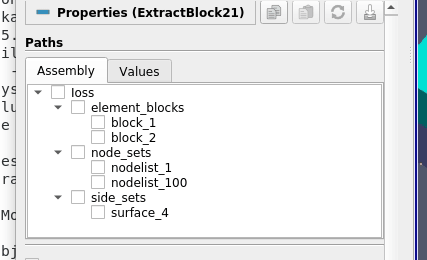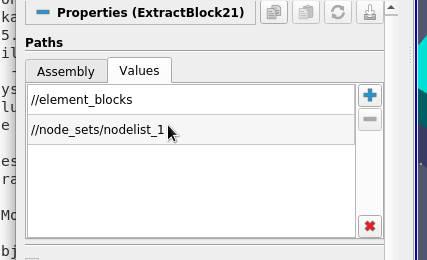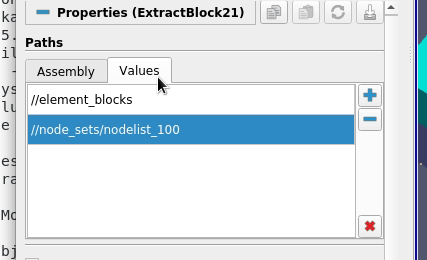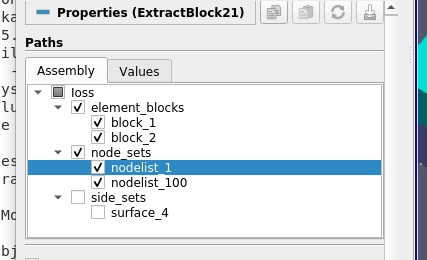
Option 2: Only show check marks for nodes that user explicitly checked. Here, the widget in the two cases will render as follows:
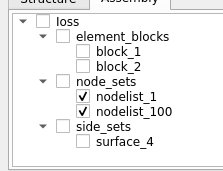
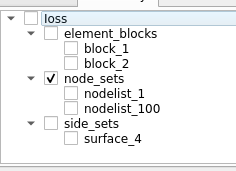
It’s fairly obvious which mode the user is going for here, so that’s good. However, note child nodes don’t reflect the check-state of the parent at all e.g. when node_sets was checked, nodelist_1 and nodelist_2 still appear unchecked.
Option 3A: Only show check marks for nodes that the user explicitly checked. However, if a parent-node is checked, for all child nodes, render them as partially-checked.
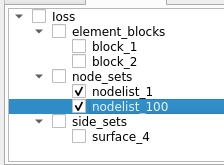
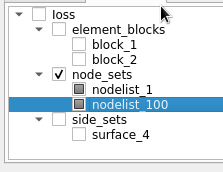
Option 3B: Same as 3A, except we use the paritionally-checked representation for parent nodes of the explicitly checked nodes as well.
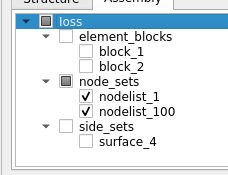
What do people think? Note, this goes beyond just Extract Block and check-states. All properties that one sets up using the Multiblock Inspector such as color, opacity etc. also will start using these paths/path-expressions in time so we should think of an solution that is widely applicable.
I have a personal preference, of course, but I’ll hold that back for now.