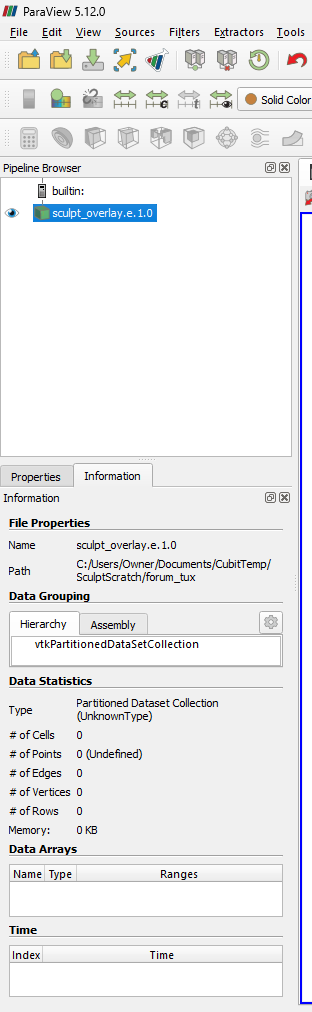
@wascott - this might be relevant to Sandia. We have a user who posted a question on our forum… if I run the below sculpt_overlay.i file in the sculpt distributed with Coreform Cubit 2024.3 it seems to not import into ParaView 5.12.0. To replicate, download the three files below:
@cory.quammen – If one wanted to look to find information about how to update our tool to export Exodus files that are compatible with the (new?) IOSS readers, where’s the best place to look?
I am able to load your examples simply by renaming them. Remove the .1.0 from each file and try again. The final number (0 in this case) should be ≥ the prior numbers.
There should probably be a bug report as we should still be able to load improperly named files. It may be a bug in VTK’s file-series reader rather than the ioss reader itself.
Hmm… well that is interesting. However, regarding the .X.Y – I do believe it is Exodus convention for X = num_partitions and Y = partition_id, for example:
Looks like @dcthomp provided the useful info here. There really shouldn’t be any changes needed (and hence no documentation for what you need to change) as the IOSS-based Exodus reader is intended to read Exodus files produced long before it existed.
The file series identification works properly with these single files, identifying that there is 1 partition and that the file corresponds to partition 0. Tracing this through to the IOSS library, I came across a conditional that fails in this scenario:
Since num_processors is equal to 1 instead of greater than 1, the block of code that appends the number or processes and the process number to the base file is skipped, leaving the decoded name as the base file name. This file of course does not exist, hence the error messages you are seeing.
If I modify that conditional on Ioss_Utils.C to read if (num_processors >= 1) { and recompile ParaView, the files load no problem.
I’d like to get @Gregory_Sjaardema 's input on this - should IOSS handle these single data files following the parallel naming conventions? Or should ParaView do something special in this case?
That is the (unwritten) convention for “decomposed file-per-rank” files. I haven’t seen anyone use it for undecomposed files before. We can probably make it work, but I would also contact the generator of the file to see why they are using this since it is confusing and adds no information.
In the file-per-rank decomposed files (#ranks > 1), the file.<#rank>.<rank#> case, I know that these files are the result of a parallel decomposition for <#rank> ranks and that the files contain the extra communication data that is needed to set up communication maps.
I also know that the user wants to run that file on <#ranks> ranks and is not valid for any other rank count for the analysis code.
I can support this case since it logically follows the #rank>1 cases, but then do I logically also follow that this file can be used on one and only 1 rank analyses?
Also what convention should be followed when/if a user takes this file and decomposes if for, for example, 4 ranks… Are the decomposed files named file.e.1.0.4.0 … file.e.1.0.4.3?
@Gregory_Sjaardema – it appears that sculpt produces files in this unwritten convention if run on one core. I’ll start a discussion with Sandia development team to see if they’d be on-board with revising this behavior.