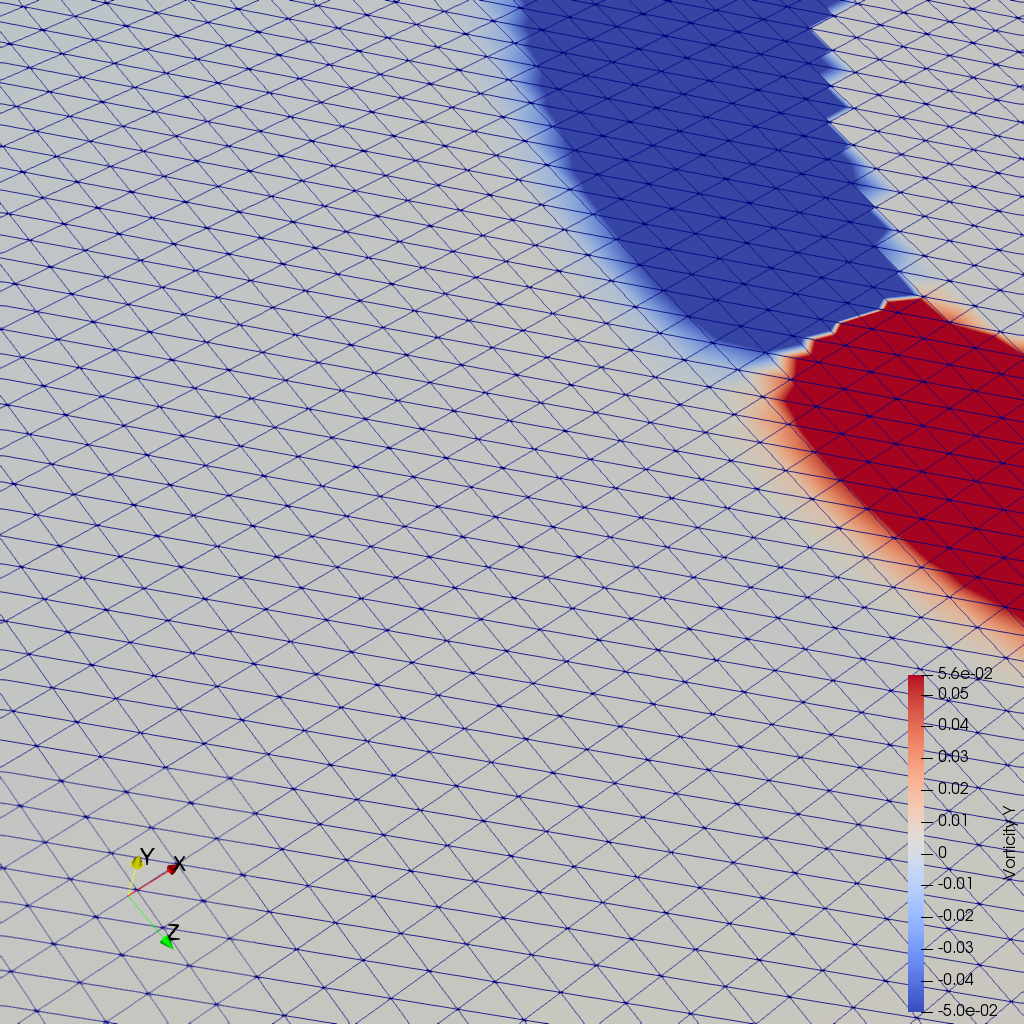
I am seeing color artifacts at process boundaries when computing vorticity of an ImageData with GradientOfUnstructuredDataSet. As seen in the attached images, doing 3, 5 or 7 pvserver tasks. This is very annoying because a volume rendering of vorticity will show these higher unwanted values.
How many layers of ghost cells should the vorticity computations require? I have tried inserting a D3, with 2 layers (minimum) and “duplicate cells” option, but still I see these artifacts. In any case, I thought PV would be smart enough to know how many ghost cells to request from my reader (Xdmf2), and D3 should be superfluous.
it turns out that I can get rid of artifacts by replacing the GradientOfUnstructuredDataSet by a PythonCalculator computing the curl of my velocity (Expression = ‘curl(inputs[0].PointData[“data”])’
here are two images running 5 pvservers tasks. Although there are small differences in overall scales, the artifacts are gone and that was my purpose. Yet, I’d like to understand what causes the artifacts of GradientOfUnstructuredDataSet
Just to be clear, are you taking a slice of the domain to show the interior in the images here? I’m confused as to why the surface shows triangles.
Any chance you could share your dataset? I wasn’t able to reproduce with my own image data. Note that the Python Calculator’s curl() function uses vtkCellDerivatives to compute vorticity.
It looks like the XDMF reader isn’t properly providing ghost information. This may also be causing problems with the D3 filter as well. I saved out the data as an image data and then read it back in parallel and the Gradient of Unstructured Data Set worked properly in parallel.
An ok workaround for this would be to convert to unstructured grid using something like a Clip filter and then use the Ghost Cells Generator filter. With this the Gradient of Unstructured Data Set filter doesn’t have any artifacts at the partition boundaries.
In my opinion, I’d be a bit suspicious of the other methods of computing gradient quantities in ParaView as I think they’re less tested.