Hi Sebastien,
I mean, when I run with “osmesa” package on a GPU node, it runs much faster than running the same package on a node without GPU. I did some new benchmarks:
1.
Version: 5.10.1-MPI
CPU: Intel Xeon 6138 (20 cores, 40 threads) or Intel Xeon 6230R (26 cores, 52 threads)
GPU: None
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem=20G --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "Display is not accessible on the server side. Remote rendering will be disabled."
Time: 1m57s
2.
Version: 5.10.1-MPI
CPU: Intel Xeon 6126 (12 cores, 24 threads)
GPU: NVIDIA P100
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem
=20G --partition=accel --gpus=1 --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "Display is not accessible on the server side. Remote rendering will be disabled."
Time: 1m46s
3.
Version: 5.10.1-MPI
CPU: AMD EPYC 7542 (32 cores, 64 threads)
GPU: NVIDIA A100
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem
=20G --partition=a100 --gpus=1 --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "Display is not accessible on the server side. Remote rendering will be disabled."
Time: 1m11s
With the MPI package, the time is always more than a minute and the message about rendering disabled appears.
The AMD CPU performs much better than both Xeon CPUs.
4.
Version: 5.10.1-osmesa
CPU: Intel Xeon 6138 (20 cores, 40 threads) or Intel Xeon 6230R (26 cores, 52 threads)
GPU: None
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem=20G --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "None"
Time: 59s
5.
Version: 5.10.1-osmesa
CPU: Intel Xeon 6126 (12 cores, 24 threads)
GPU: NVIDIA P100
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem
=20G --partition=accel --gpus=1 --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "None"
Time: 48s
6.
Version: 5.10.1-osmesa
CPU: AMD EPYC 7542 (32 cores, 64 threads)
GPU: NVIDIA A100
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem
=20G --partition=a100 --gpus=1 --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "None"
Time: 20s
With the OSMESA package, even though the CPUs are the same, having GPUs reserved make a huge difference.
On the first case (MPI package), it performs faster than with the AMD CPU and no GPU
With the P100 and A100, both perform much better too, being the A100 faster (it is also the newer and more powerful that we have available)
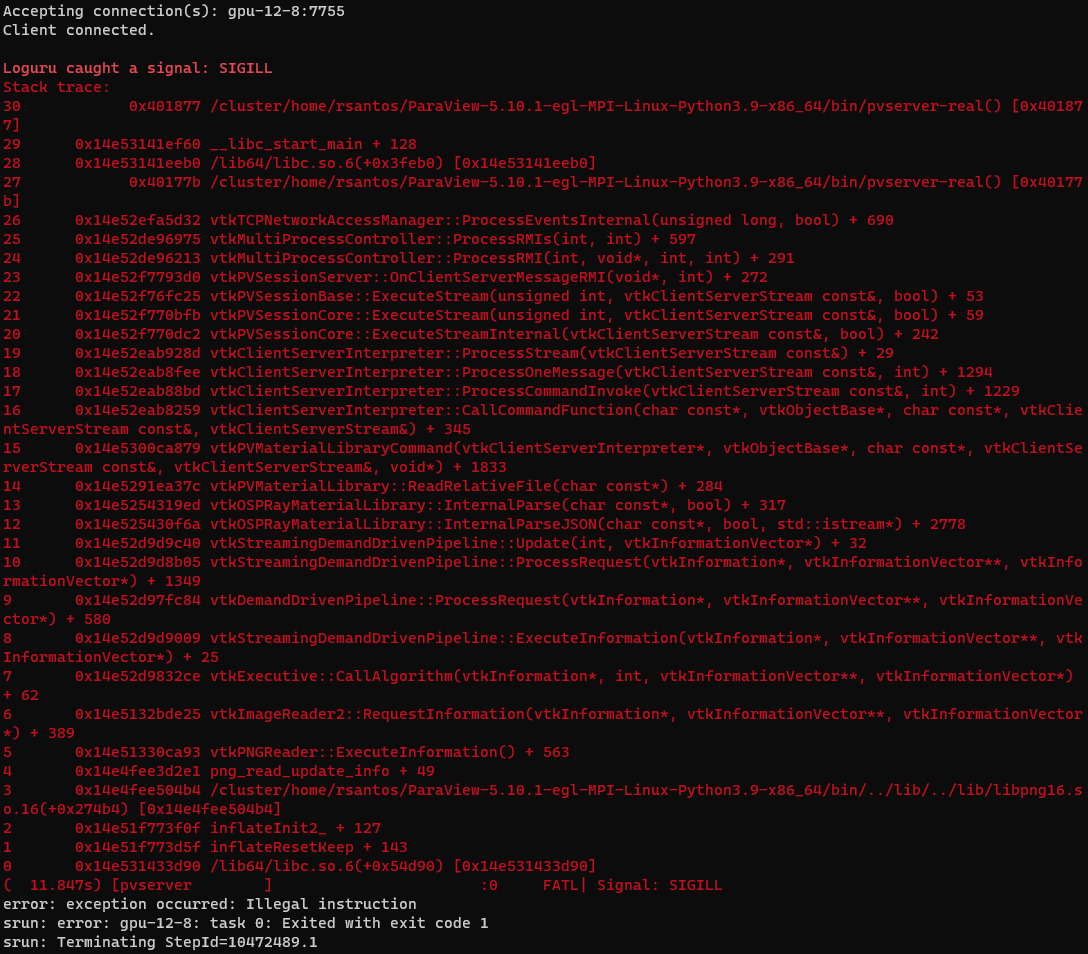
7.
Version: 5.10.1-egl
CPU: Intel Xeon 6138 (20 cores, 40 threads) or Intel Xeon 6230R (26 cores, 52 threads)
GPU: None
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem=20G --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "error while loading shared libraries: libOpenGL.so.0: cannot open shared object file: No such file or directory"
Time: did not run
8.
Version: 5.10.1-egl
CPU: Intel Xeon 6126 (12 cores, 24 threads)
GPU: NVIDIA P100
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem
=20G --partition=accel --gpus=1 --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "None"
Time: 47s
9.
Version: 5.10.1-egl
CPU: AMD EPYC 7542 (32 cores, 64 threads)
GPU: NVIDIA A100
Allocation command: `salloc --nodes=1 --ntasks-per-node=1 --cpus-per-task=1 --time=00:30:00 --mem
=20G --partition=a100 --gpus=1 --account=nn9999k`
PV Server command: `srun ./pvserver --server-port=7755 --force-offscreen-rendering`
Message: "None"
Time: 19s
With the EGL package, we do not see too much difference from the OSMESA version. The MPI package did not run and, even though I managed to load the “libOpenGL.so.0”, it gave me error when connecting to PV Server.
In summary, we can see CPU differences on the first category, but GPU really seems to make a difference. Also, I was expecting EGL to be much faster than OSMESA but this is not the case.
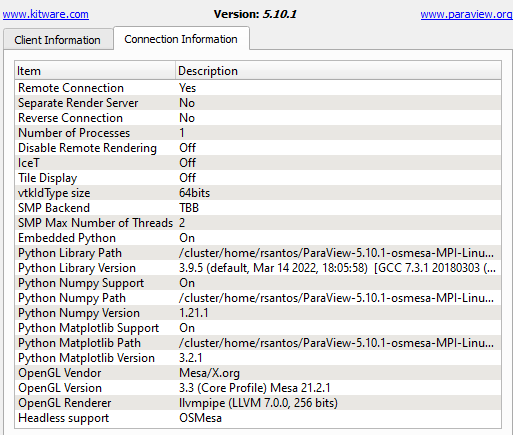
As for your questions, I am loading a 1gb file that renders a 3d cube and I measure from the time I click on “Apply” until the cube renders on the screen and I can move with my mouse.
The user that I am supporting provided the file and I don’t have more knowledge about ParaView so I am not sure about the default rendering backend you mentioned.
What I did was basically downloading the “MPI”, “OSMESA” and “EGL” files from ParaView website, unpacked the tar files on the server and ran pvserver like I wrote above. All versions are 5.10.1, including the one I am running on my laptop (and connecting to PV Server) on Windows 11.
I tried to play a bit with ntasks-per-node and cpus-per-task, but it did not make a lot of difference. Also, the flag --force-offscreen-rendering seemed to always make it run slightly faster, but again, a very marginal difference.
Finally, the user complained that he was trying to load a 53GB file and it took 37 minutes before ParaView just crashed and he did not manage to load his file (when he was using the MPI version). Once he started using the OSMESA version like on the benchmark 6, the same file loaded within less than 7 minutes.
Sorry for the long post, I just wanted to provide more context and try to understand why the GPU node makes a difference, especially for updating our documentation.
Best Regards,
Rafael