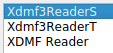
I have been using the “XDMF Reader” which implements xdmf1, maybe?
The issue that I have with this one is that HyperSlabs are rediculously slow and file reading is not parallelized either.
“XDMF Reader” is version 2 of libXDMF. It should still be doing parallel reads of large monolithic structured data content files.
The other two use version 3 of libXDMF. Neither do the parallel split of large structured data content that xdmf2 did. “S” and “T” options vary in how they treat numbered sequences of xdmf files. “T” treats them as a time series similarly to XDMF2. “S” treats them as a spatial partitioning instead. The option effects parallelization strategy of multiblock data as well, reading leaf nodes “T” or entire trees “S” independently as well. For grid of trees data “S” can be significantly faster in parallel.