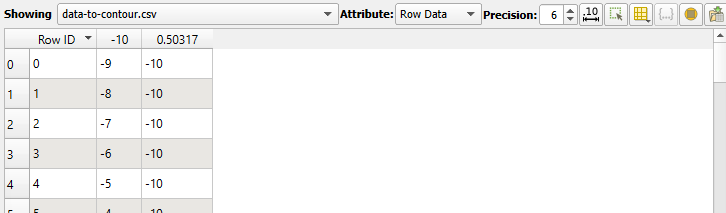
I have a .csv file with three columns and 441 rows. It is completely numerical. This csv was generated by Kenneth Moreland in his excellent answer to 2D contour from .csv as a test file.
When trying to import this into paraview, I only get two of the three columns, plus a column called “row ID”.
Might just add as I had the same issue recently:
Make sure the last data line in the CSV file does not have a trailing whitespace. This also leads to Paraview not showing the last column.
This is an excellent tip, definitely something to watch out for.
I’ll also add that python is great for avoiding any potential issues with a weird csv file. Pandas makes filtering out things you don’t want - excess headers, comments, bad data, really easy.
For example, I use the following code for one particular file I get from another program which loves to add comments to my data, and uses -1 instead of NaN:
import numpy as np
import pandas as pd
df = pd.read_csv(r"C:\Users\User\yourdata.txt",
comment='#',delim_whitespace=True, header=None,
)
df.columns =['qx', 'qz', 'counts'] #these are the x, y, and z labels for my data, which is a 2D XRD scan if you're curious.
df['counts'] = df['counts'].mask(df.counts < 0) #change negative values to NaN
for series_name, series in df.items():
name = series_name
array = series.to_numpy()
output.RowData.append(array, name)
This is probably my favourite method so far, I don’t love the default CSV reader. But when I’m following a tutorial I think it’s best that I don’t do anything fancy haha.
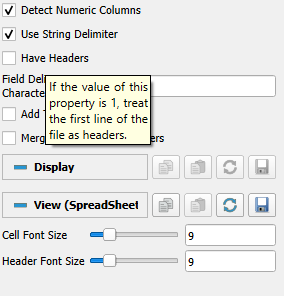
Also, if the data doesn’t have headers, it helps to make sure that this box is not ticked!! A semi-obvious solution - I assumed that this wouldn’t case issues and that the first line of data would become a header, but it seems that wasn’t the case.