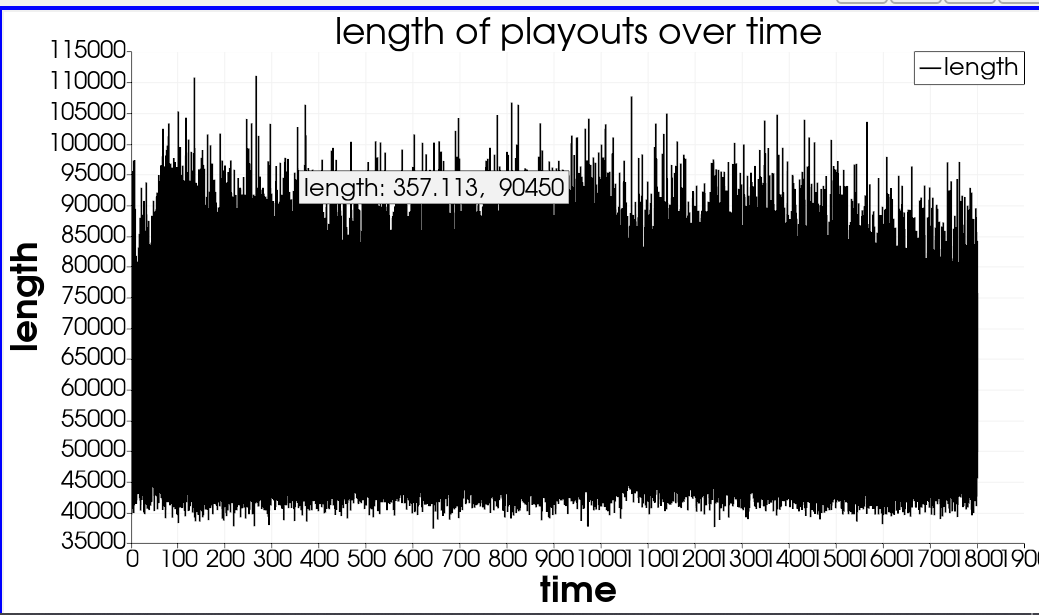
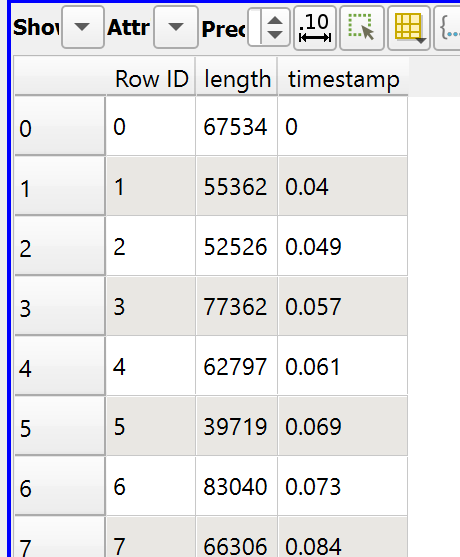
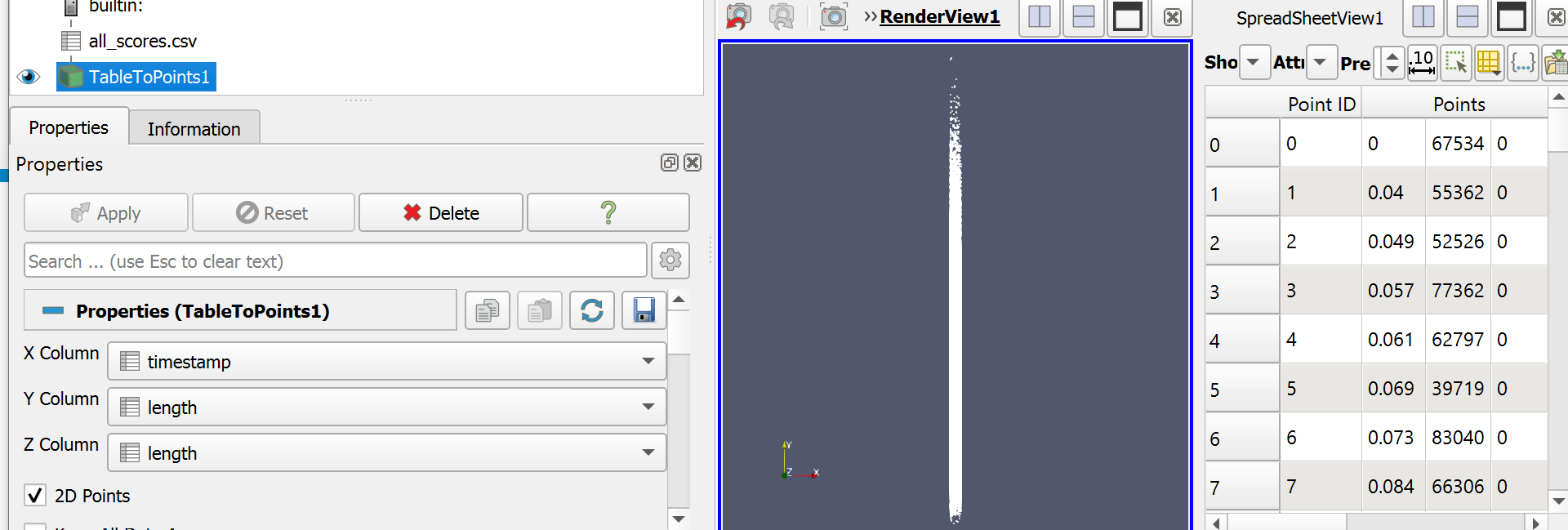
I already made some test with python and Matplotlib and if instead of plotting all points I plot 1 point for 1000 at the average timestamp with the average length of the 1000 points, the graphic can actually be exploited.
Can I do this in Paraview or do I have to use external tools ?
There is a decimate filter in ParaView but it works only on geometrical data (vtkPolyData) not on pure table (vtkTable). you could convert your data to polydata though.
I can’t use the decimate filter I got : ERROR: In C:\glr\builds\paraview\paraview-ci\build\superbuild\paraview\src\VTK\Filters\Core\vtkDecimatePro.cxx, line 160 vtkDecimatePro (000002CD91D56380): No data to decimate!
To do this, do I have to read the .csv inside my python script, or can I use the plot data object generated by paraview ? As I have a lot of points I fear that reading the csv with python will take too long
import numpy as np
# assuming data.csv is a CSV file with the 1st row being the names names for
# the columns
data = np.genfromtxt("C:/Users/Clement/Documents/prepa/tipe/ocaml-tsp/logs/MCTS-att48-1800s-Random-Min_spanning_tree-Two_opt_optimization_200len_100iter_1s--1/all_scores.csv", dtype=None, names=True, delimiter=',', autostrip=True)
for name in data.dtype.names:
a = np.array(data[name])
m = 1000
b=a[:len(a)//m*m].reshape(-1, m).mean(1)
# You can directly pass a NumPy array to the pipeline.
# Since ParaView expects all arrays to be named, you
# need to assign it a name in the 'append' call.
output.RowData.append(b, name)
I don’t know how I can use the csv file inside paraview as an input I guess it would be with a programmable filter ? This would be better than just manually writing the path to the file as I did. Also, it would be nice if m was a parameter for the filter
@smproperty.intvector(name="ReductionFactor", default_values=16)
def SetReductionFactor(self, x):
if x <= 0:
print("Error : the reduction factor has to be a greater or equal to 1")
raise Exception("the reduction factor has to be a greater or equal to 1")
self._realAlgorithm.SetReductionFactor(x)
self.Modified()
How can I get the ReductionFactor when RequestData is called ?
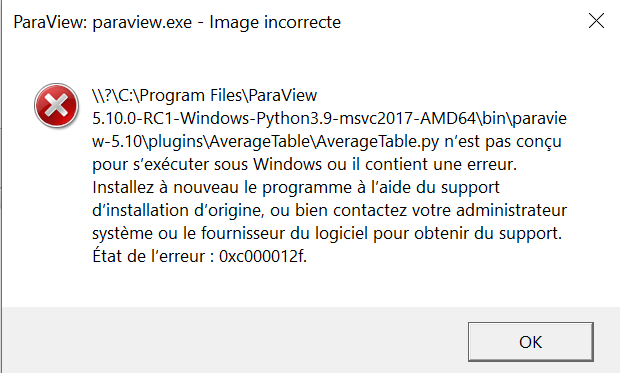
Also here is my current code Python plugin paraview - Pastebin.com (not using the ReductionFactor for now). For now when I try to import it I get this error :
Generic Warning: In C:\glr\builds\paraview\paraview-ci\build\superbuild\paraview\src\Remoting\ServerManagerPython\vtkPVPythonAlgorithmPlugin.cxx, line 184
Failed to load Python plugin:
Failed to call `paraview.detail.pythonalgorithm.load_plugin`.
Traceback (most recent call last):
File "C:\Program Files\ParaView 5.10.0-RC1-Windows-Python3.9-msvc2017-AMD64\bin\Lib\site-packages\paraview\detail\pythonalgorithm.py", line 509, in load_plugin
spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 855, in exec_module
File "<frozen importlib._bootstrap>", line 228, in _call_with_frames_removed
File "C:\Program Files\ParaView 5.10.0-RC1-Windows-Python3.9-msvc2017-AMD64\bin\paraview-5.10\plugins\AverageTable\AverageTable.py", line 2, in <module>
@smproxy.filter()
NameError: name 'smproxy' is not defined
ERROR: In C:\glr\builds\paraview\paraview-ci\build\superbuild\paraview\src\Remoting\Core\vtkPVPluginLoader.cxx, line 532
vtkPVPluginLoader (000001F652730CC0): C:\Program Files\ParaView 5.10.0-RC1-Windows-Python3.9-msvc2017-AMD64\bin\paraview-5.10\plugins\AverageTable\AverageTable.py: %1 n’est pas une application Win32 valide.
Could you please clarify when do you have this error? Immediately after attempt to import plugin through ParaView GUI (Tools->Manage Plugins…->Plugin Manager->Load New …)? Or did you add this plugin to a list of autoload plugins?
By the way, what do you want to view in ParaView? Just a set of points (x_i = t_i, y_i = length_i according your csv file) with the possibility to merge every m (e.g. m = 1000) points with averaged length? For this you can use python libraries (e.g. for signal processing) to decimate the signal inside your plugin for ParaView or inside other python script before loading the data into the ParaView. Why do you not use precompiled binaries of stable version of ParaView?
Yes this is what I’m trying to achieve. I just don’t know how to do it properly. I guess I could use scipy.signal.decimate for example. I’d like to do it in paraview because I prefer an overlay in which I can select the downsampling factor rather than a python script. If you have a code ready to use that would be awesome.
Also if there is a precompiled binary that does this it would be enough for me xD