I am dealing with a large amount of data which involves multiple data sets for any given case study. Each case has different slices, and each slice has different fields. So the data tree, so to speak, looks something like:
- SP214
- Full
- displacement
- strain
- Slice
- 1
- displacement
- strain
- 2
- displacement
- strain
- 3
- displacement
- strain
- 1
- Full
So the path for some of the data sets of the above tree would for example be
/home/data/SP214/Full/displacement/full-displacement..vtu/home/data/SP214/S3/strain/strain..vtu
The data directory tree is consistent for all cases, but I admit it may not have the best structure for paraview. With that said, some times I would like to see all of the available data together. Other times I only want to see the “full displacement” along with “strain S2”. Given that the path names are consistent, I can’t help but think that there is a way to automate the loading of these data sets in Paraview. Ideally, I would have a GUI where I can check off what I want to load, e.g.
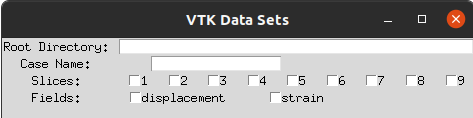
I’ve thought about using multi block data sets, but then I found that multi blocks will be deprecated so I decided against them since I would like this to work more long term. Another (not automated) approach I had was to save the state and then replace the case name in the *.pvsm file. This is definitely not ideal.
What is the best approach for creating this sort of tool? Would I need to write a reader sub-class to read multiple data sets? Would this be a plugin? Better yet, is this even possible?