Multiblock Datasets (vtkMultiBlockDataSet) have been used in ParaView for representing a collection of datasets. Besides being a container for multiple datasets, called blocks, it also lets us define relationships between those blocks in an hierarchical fashion. While conceptually this sounds great, in practice, the implementation introduced several challenges especially for developers writing algorithms that worked with multiblock datasets in distributed fashion. Some of the challenges are as follows:
It’s not easy to distinguish between blocks that are parts of whole i.e. simply split into chunks for parallel processing or blocks that define logical grouping .e.g. assemblies. While vtkMultiPieceDataSet was supposed to help there, in practice, it’s hardly used.
The hierarchy needs to be consistent across ranks with parallel processing. This causes undue burden on readers/filters which then often resort to merging blocks together.
The index used to identify nodes (called composite-index) is unintuitive and affected by even the slightest change to the hierarchy.
Initially, the thought was we’d start slowing converting readers that produce multiblock datasets to use this new data model and thus reduce usage of multiblock datasets to a point where we can deprecate them for good. With that in mind, when time came to rewrite the Exodus reader, we opted to implement that reader to produce this new data model. The reader was easy. The new data model did indeed make it lot easier to write this reader which no longer had to do crazy gymnastics to ensure that the structure lined up across all ranks. However, the devil is always in the details and that’s where things started getting more complicated than easier. Now, for this reader to be usable in ParaView, filters and UI components need to support 2 different datasets: multiblock datasets and the new paritioned-dataset collections. That means additional complexity in several of these already complex filters – even if this was only until we removed the multiblock dataset related logic.
Rather going down this highly unmaintainable path, here’s another alternative: we deprecate multiblock datasets right off the bat!
After the initial shock has subsided, if we think about what this exactly means, it may not be too hard of a pill to swallow (or so I hope).
Core components of ParaView that currently use multiblock datasets will be converted to use partitioned-dataset collections instead. Thus, filters like Restribute Dataset, Resample Dataset etc. that will need to be converted. Same is true for rendering components i.e. mappers, multiblock inspector etc etc. From user’s point of view, these are all internal changes. In fact these may be a little better since now, instead of using some silly composite-index to set block colors and other properties in the Multiblock Inspector, for example, the user will use block names which are more intuitive.
Now, what about all the readers that are reading in multiblock datasets? While overtime we should convert all of such readers and data producers, in the interim, we will develop a filter that converts any multiblock dataset to partitioned-dataset collection + data-assembly. ParaView can internally apply this filter so that users don’t have to explicitly use it. This lets all existing multiblock sources continue to work.
To support custom filters that only work on multiblock datasets, we develop a filter that converts a partitioned-dataset-collection + data-assembly to a multiblock-dataset – inverse of the filter described earlier. This too can be automatically applied under the covers by ParaView when it encounters a multiblock filter being applied to a partitioned-dataset collection pipeline.
My question is specific to parallel-unaware filters relying on multiblock architecture in order to parallelize work. Will this mechanism be ported to partitioned dataset as well ?
This sounds practical, but is a little scary because the changes sound extensive. So long as we can be testing prior to release, I reckon we can keep things happy on the user side.
I’d think we’d shoot for spring 2021 release (v5.10). Start working on various parts now and make them active in master soon after the 5.9 release. That should give us most of the 5.10 release cycle to identify pitfalls and address issues.
Is this going to affect code like this: MultiBlockDataSet or WarpCombustor? If so there are about 30 examples that will need to be modified. Also the equivalent Python examples (if they exist).
If modifications are needed please give me some ideas. I’m happy to do the work. The VTK version macros will come in use here!
This sounds frightening, but sounds like the only way, and a very logical way, to move forward. I’m convinced we have got to move forward from the old Exodus reader. That thing is going to sink some day soon from all of the barnacles surrounding it.
Is this a big enough change in the code to justify calling this ParaView 6.0? Maybe include the update to the toolbars at the top of ParaView?
They don’t need to be updated in the first pass, but ideally should be. I can definitely help with that. Just looking the two examples, the changes should be fairly minimal, once we have the reader converted over to producing vtkPartitionedDataSetCollection – which itself is quite easy here too.
This is a bold move but it seems fair. Is the vtkDataAssembly designed to replace Subset Inclusion Lattice ? Can multiple vtkDataAsssembly be used over a partitioned dataset collection ?
Presumably not a large problem for our generators within OpenFOAM - they generate multiblock for topologically different items and multipiece for handling ranks, which likely map OK.
But what becomes of the .vtm format?
Based on our discussion earlier about selection mechanisms offered by readers, SubsetInclusionLattice for selecting which blocks should simply be removed. Readers can offer format-specific simpler selection, all of which can simply use vtkDataArraySelection instances (which should probably be renamed, since it can be used for other things than just array-selection).
The other conceptualized use-case – but not implemented yet – was to allow setting up of block parameters or selection (in case of filters like Extract Block) using the SubsetInclusionLattice. That would indeed be replaced by vtkDataAssembly.
That was indeed a use-case we were considering. Currently, it doesn’t; only one vtkDataAsssembly is supported. However, it should be possible to support that in the future – just needs a little more thinking about ramifications etc.
Indeed. Should be a trivial change.
There’s .vtpc which is replaces .vtm. However, when Multiblock Dataset is totally removed, we can make the .vtm reader produce a PartitionedDataSetCollection + DataAssembly instead (similar to the vtkDataObjectToPartitionedDataSetCollection filter under development).
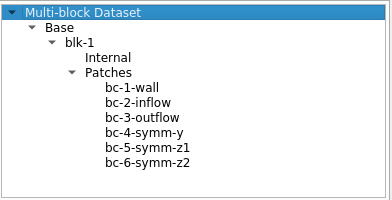
Here’s the current output from a CGNS file. The multiblock looks as follows:
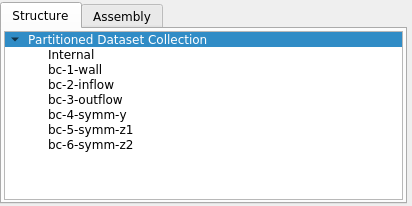
On converting this to vtkParitionedDataSetCollection using the vtkDataObjectToPartitionedDataSetCollection filter, it looks like this:
The data-assembly captures the relationships as follows:
Thus, this for filters that care about the relationships, they have all information necessary via the DataAssembly.
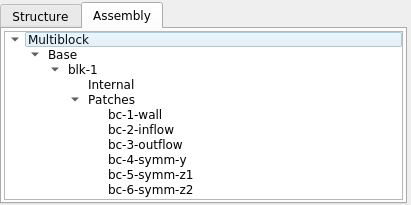
Now, by applying the vtkPartitionedDataSetCollectionToMultiBlockDataSet to convert this paritioned-dataset-collection back to multiblock, we get the following:
In the case of CGNS, we can have /Base/blk1/Internal and /Base2/blk1/Internal in the same file. Thus we do not have unicity of block naming without the full path. I suspect it can be the same with vtm files.
Is it an issue ?
Not at all. Names in the Structure are just helpful hints and not needed to be unique. The assembly would indeed have full hierarchy. Users will be using the assembly to set color and other parameters in the Multiblock Inspector or in filters like Extract Block; so there won’t be any ambiguity.