The ParaView files of flow simulations using 1, 5, 20 and 82 million particles are available from a research data repository under a plain CC BY license. I imagined that the community of ParaView developers and users may find pre-computed datasets with 82M particles useful for benchmarking the performance/robustness of their visualization and data-analysis algorithms.
The flow is a so-called dam break: a block of still water is allowed to slide and hits a wall at some distance downstream. Interestingly, the flow features a first stage where the trajectories are smooth and orderly, and a second when the motion is definitely chaotic after countless rebounds and splashes. (The simulations have been carried out with a particle-based method called SPH for Smoothed Particle Hydrodynamics.)
Please have a look at the YouTube playlist for a first visual appreciation: The 2D dam-break benchmark dataset • SPH solutions - YouTube. Note that, for your convenience, each video has a detailed explanation of its content, context and purpose. (Of course: all has been rendered in ParaView!)
The datasets contain, for each particle count, the 201 vtk files showed in the playlist animations. These files are available from the certified repository 4TU.ResearchData in the Netherlands. You can visit it via the link below:
If you are interested, the following navigation tips can be handy.
The collection where you land groups five datasets.
One ‘gateway’ dataset contains all information needed to decide what to do with it next. In particular a Commentary.pdf document explains the origin and architecture of the collection.
Then, the other data sets contain the files at the different particle counts (1, 5, 20, 82 millions): there you find a compressed vtk file for each frame with a consistent naming WaterParticle_???.vtk.xz
The total size of the collection is 735GB and consists of 1650 files. You can download either entire datasets or individual files.
I recommend to read the Commentary first.
I hope that sharing these large datasets can be useful also from the perspective of post-processing.
If this community uses Twitter as well, this legacy tweet contains the announcement and links:
(Sorry I forgot the hashtag #RenderedInParaView then!)
The postdoc project that generated this collection is finished in the meantime and that Twitter account is not maintained any longer.
Thanks a lot!
I tried loading all the vtk files (low res case) into Paraview but get a reading error. Does it require any specific plugin to load the files?
@Cristian24 Thanks for raising a flag. No plugin is needed.
Please note that the vtk files in the repository are compressed: decompressing the xz file into native vtk format should not be difficult (see Section 3.3.5 of the Commentary for tips). The compression pass also added the information to perform a file integrity control at the point of decompressing. So, once you manage to decompress successfully, the file is guaranteed to be the original.
If you met an exception nonetheless, would you please mention which specific file gave you hard time? There is a small but nonzero possibility that the file transfer from the compute node to the data repository resulted in an undetected corrupted copy. This might have corrupted the xz file and/or its vtk content. It would be helpful to record if this happened.
@mwestphal Sorry for the late reply. The repository offers a deposit time of about five to ten years, anyhow order of magnitude larger than this incident. Perhaps it was a temporary outage. Have you tried again afterwards? If you still bump into the issue, please forward me the offending link (to a document that you do not manage to download) and I will ask the data librarians.
Those who found this collection of datasets relevant for developing visualization and analysis tools, may also be interested in browsing a conference paper that discusses and illustrates them from a content-based perspective.
This conference paper is open-access under a CC-BY license from Dam Break Flow Benchmarks: Quo Vadis? | Zenodo. Also relevant for this community, the figures created with ParaView are shared open-access separately.
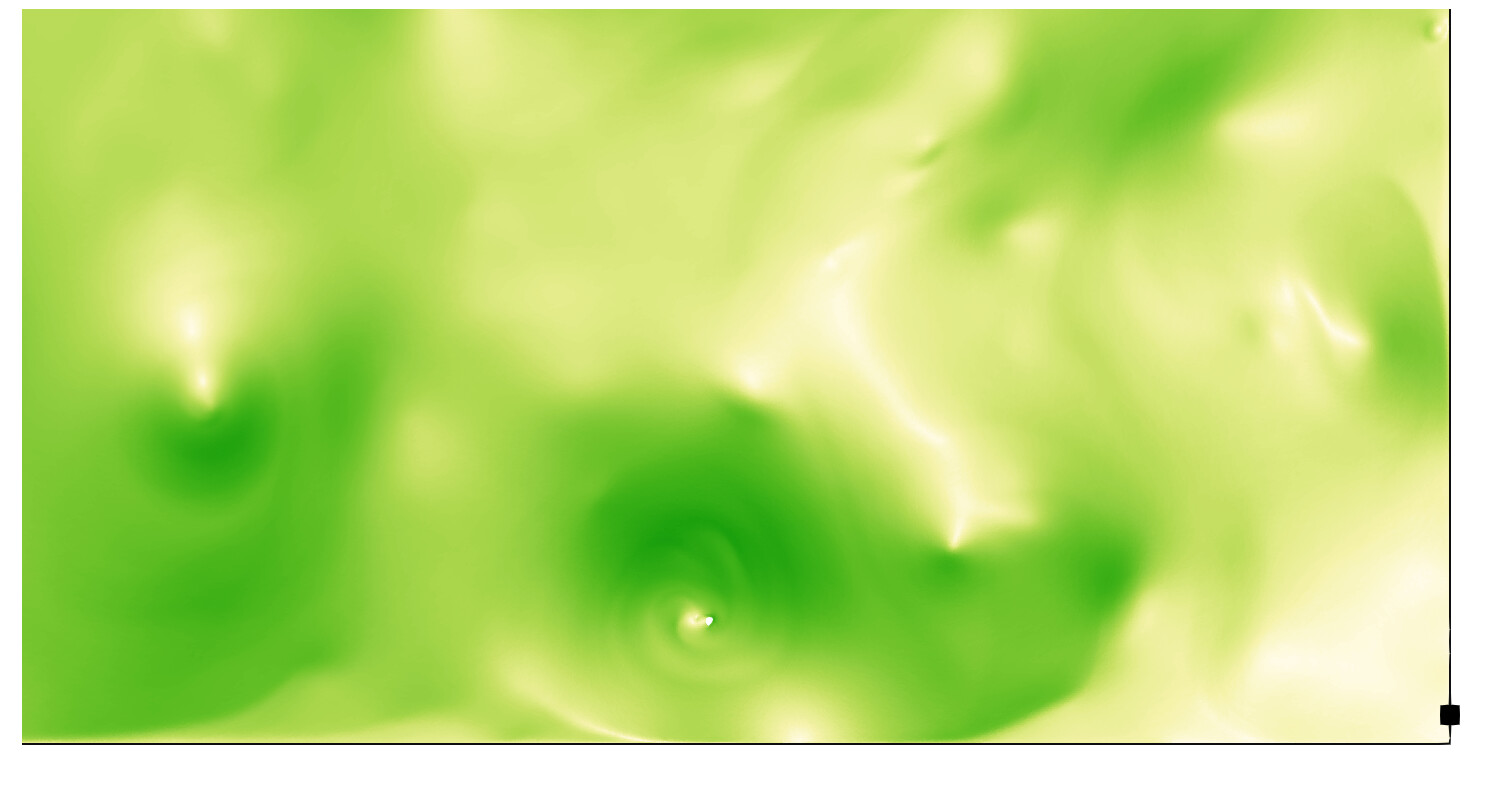
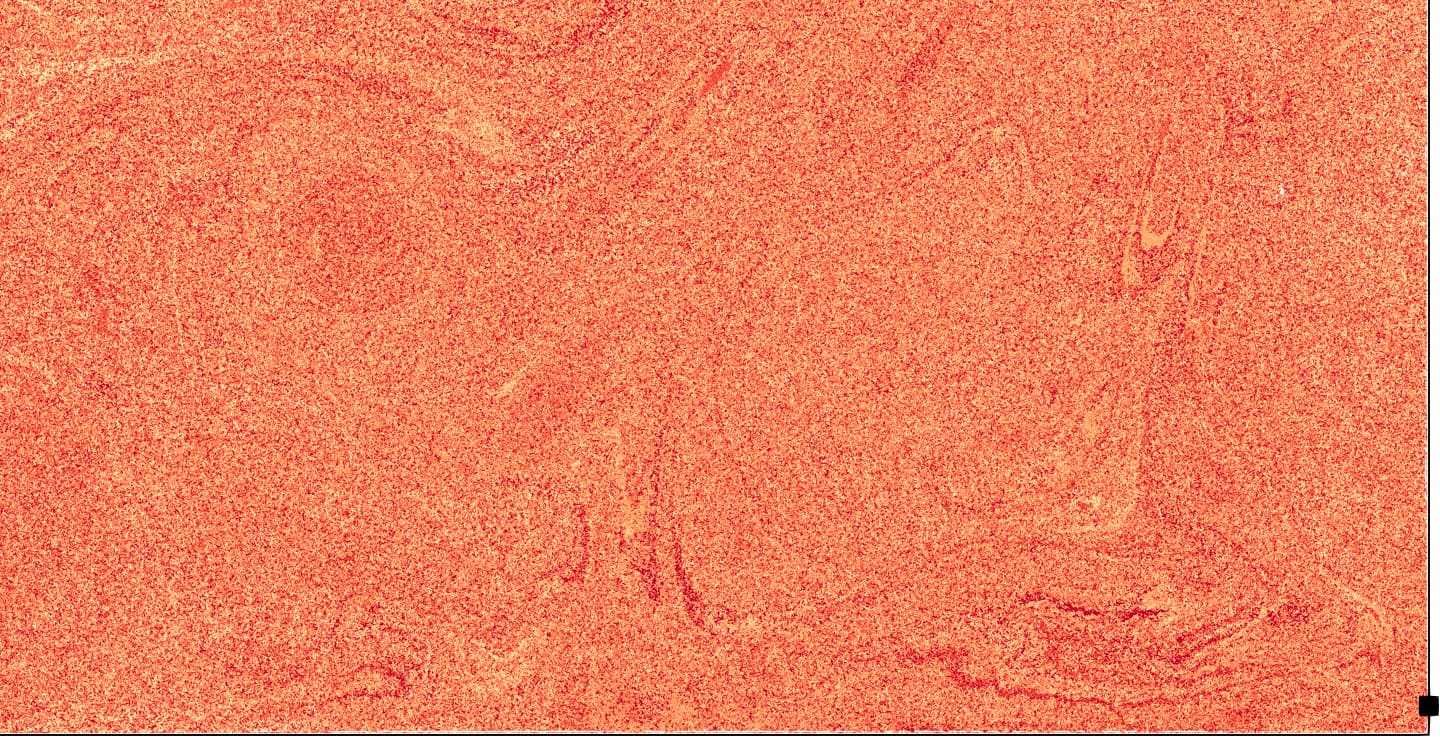
In particular, every point in the datasets contains values of velocity, density and an element identifier. You surely do not need to go into the science behind that.
However, the image shows
that all fields sometimes contain voids;
that velocity fields contain vortices (green-shaded pictures);
that density fields can contain reflected circular waves and impulses (brown-shaded pictures);
and, finally, that the identifier fields display different degrees of mixing between neighbouring elements.
These special features can provide useful test cases to develop pattern-identification algorithms and measures of (dis)order, I imagine.