Starting with 5.8.1 we have have a plugin that allows a single button click to save a .pvsm state file with a matching .png and empty .txt file all with the same name, different extensions. (saveStateandScreenShot Plugin) I used this capability heavily during a recent project and ended up with nearly 200 of these 3 file sets in a directory that was shared with the team via git. If I wanted to load a state into ParaView I found it most convenient to use my Ubuntu or mac OS file browser, identify the image I wanted to load, then drag and drop the pvsm onto a running ParaView which automatically loaded the pvsm. I’ve done this a lot in the last month and have some possible Improvements to using the pvsm system:
-
When opening in ParaView there is a first order distinction that needs to be made as to whether you are opening data or a state file. Why can’t this be a common open and have paraview (rather than the user) deal with a pvsm vs data file? Wouldn’t that simplify the interface? (I frequently clicked one when meaning the other, navigated for a long time only to find out I picked the wrong thing to open.)
-
When browsing for a pvsm, it would be very convenient if ParaView recognized a same named png and provided an image in the file browser that would allow a user to identify the associated pvsm, maybe even somehow show the contents of the associated text file, maybe in a pane?
-
When loading a pvsm it would be nice if it ParaView didn’t automatically process the state, but rather gave you an opportunity to inspect and maybe alter the pipeline before executing the pipeline (similar to the whole discussion about apply vs. autoapply)
-
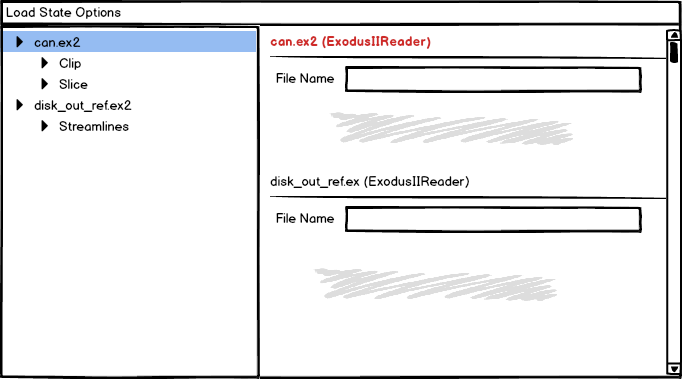
When loading a pvsm a window pops up that allows you to adjust the locations of the files that are being read, which is necessary and useful when sharing pvsms among users. Once the files are chosen, ParaView executes the pipeline. When choosing the files it isn’t clear what role each file plays in the pipeline, this makes it more difficult especially when there are many data files to read.
On a PVSM load, I could imagine the pipeline just showing up in the pipeline browser, with the capability of setting the sources (files) in the pipeline browser’s properties panel, before doing an apply rather than the popup. It would be convenient if one could change the reader’s input file from the properties panel forcing the pipeline to be updated with a new data file. (Any source that doesn’t have a proper file path could be made bold and red). I was producing new data files frequently that were on the order of 100GB a piece, it took a long time to load each one, and frequently I would pick the wrong one, after loading a pvsm with the wrong files, my options were to open a new file, get a new pipeline element and change the inputs of one or more filters that would come after, this was particularly difficult for multi input filters, making it easier to just start over. It would have been much easier if I could just change the input filename on the reader.
-
Change the input data file in a reader. This would be generally useful even without the PVSM. I guess there would be good arguments against a data file change in an already applied reader, ParaView is already kind of allowing the results of such a change by allowing the user to pick new data files during a pvsm load, I would guess the pipeline would respond the same when new data files were selected that didn’t have all of the correct scalars/data required for the pipeline.
-
For all filters that take multiple inputs, clearly show somewhere what the inputs are and what their IDs/order are.