1. The issues with vtkMultiBlockDataSet
Multiblock Datasets (vtkMultiBlockDataSet) have been used in ParaView and VTK for representing a collection of datasets. Besides being a container for multiple datasets, called blocks, it also lets us define relationships between those blocks in an hierarchical fashion.
While conceptually this sounds great, in practice, the implementation introduced several challenges especially for developers writing algorithms that worked with multiblock datasets in distributed fashion. Some of the challenges are as follows:
-
It’s not easy to distinguish between blocks that are parts of a whole i.e. simply split into chunks for parallel processing or blocks that define logical grouping, e.g. assemblies. While vtkMultiPieceDataSet was supposed to help there, in practice, it’s hardly used.
-
The hierarchy needs to be consistent across ranks with distributed processing. This causes undue burden on readers/filters which then often resort to merging blocks together.
-
The index used to identify nodes (called composite-index) is unintuitive and affected by even the slightest change to the hierarchy and requires complex offset handling to be used.
2. What are vtkPartitionedDataSet and PartitionedDataSetCollection ?
In ParaView 5.10, a new mechanism for representing data hierarchies using vtkPartitionedDataSetCollection and vtkDataAssembly has been introduced. This document describes the design details.
Data Model
The design is based on three classes:
- vtkPartitionedDataSet is a collection of datasets (not to be confused with vtkDataSet).
- vtkPartitionedDataSetCollection is a collection of vtkPartitionedDataSets.
- vtkDataAssembly defines the hierarchical relationships between items in a
vtkPartitionedDataSetCollection.
Both vtkPartitionedDataSet and vtkPartitionedDataSetCollection inherits from vtkDataObjectTree, as does vtkMutliblockDataSet.
Partitioned Dataset
vtkPartitionedDataSet is simply a collection of datasets that are to be treated as a logical whole. In data-parallel applications, each dataset may represent a partition of the complete dataset on the current worker process, rank, or thread. Each dataset in a vtkPartitionedDataSet is called a partition, implying it is only a part of a whole.
All non-null partitions have similar field and attribute arrays. For example, in a vtkPartitionedDataSet comprises of vtkDataSet subclasses, all will have exactly the same number of point data/cell data arrays, with same names, same number of components, and same data types.
Partitioned Dataset Collection
vtkPartitionedDataSetCollection is a collection of vtkPartitionedDataSet. Thus, it is simply a mechanism to group multiple vtkPartitionedDataSet instances together. Since each vtkPartitionedDataSet represents a whole dataset (not be confused with vtkDataSet), we can refer to each item in a vtkPartitionedDataSetCollection as a partitioned-dataset.
Unlike items in the vtkPartitionedDataSet, there are no restrictions of consistency between each item, partitioned-datasets, in the vtkPartitionedDataSetCollection. Thus, in the multiblock-dataset parlance, each item in this collection can be thought of as a block.
Data Assembly
vtkDataAssembly is a means to define an hierarchical organization of items in a vtkPartitionedDataSetCollection. This is literally a tree made up of named nodes. Each node in the tree can have associated dataset-indices. For a vtkDataAssembly is associated with a vtkPartitionedDataSetCollection, each of the dataset-indices is simply the index of a partitioned-dataset in the vtkPartitionedDataSetCollection. A dataset-index can be associated with multiple nodes in the assembly, however, a dataset-index cannot be associated with the same node more than once.
An assembly provides an ability to define a more complex view of the raw data blocks in a more application-specific form. This is not much different than what could be achieved using simply a vtkMultiBlockDataSet. However, there are several advantages to this separation of storage (vtkPartitionedDataSetCollection) and organization (vtkDataAssembly). These will become clear as we cover different use-cases.
While nodes in the data-assembly have unique ids, public facing algorithm APIs should not use them. For example an extract-block filter that allows users to choose which blocks (rather partitioned-datasets) to extract from vtkPartitionedDataSetCollection can expose an API that lets users provide path-expression to identify nodes in the associated data-assembly using their names.
Besides accessing nodes by querying using their names, vtkDataAssembly also supports a mechanism to iterate over all nodes in depth-first or breadth-first order using a visitor.
vtkDataAssemblyVisitor defines an API that can be implemented to do custom action as each node in the tree is visited.
Design Implications
Since vtkPartitionedDataSet simply contains parts of a whole, there is no specific significance to the number of partitions. In distributed pipelines, for example, a vtkPartitionedDataSet on each rank can have arbitrarily many partitions. Furthermore, filters can add/remove partitions as needed. Since the vtkDataAssembly never refers to individual partitions, this has no implication to filters that use hierarchical relationships.
When constructing vtkPartitionedDataSetCollection in distributed data-parallel cases, each rank should have exactly the same number of partitioned-datasets. In this case, each vtkPartitionedDataSet at a specific index across all ranks together is treated as a whole dataset. Similarly, the vtkDataAssembly on each should be identical.
When developing filters, it is worth considering whether the filter really is a vtkPartitionedDataSetCollection filter that simply operates between data sets, or rather a vtkPartitionedDataSet-aware filter that needs to operate on each vtkPartitionedDataSet individually. For example, typical multiblock-aware filters like ghost-cell-generation, data-redistribution, etc., are simply vtkPartitionedDataSet filters. For vtkPartitionedDataSet-only filters, when the input is a vtkPartitionedDataSetCollection, the executive takes care of looping over each of the partitioned-dataset in the collection, thus simplifying the filter development.
Filters that don’t change the number of partitioned-datasets in a vtkPartitionedDataSetCollection don’t generally affect the relationships between the partitioned-datasets and hence can largely pass through the vtkDataAssembly. Only filters like extract-block that remove partitioned-datasets need to update the vtkDataAssembly. There too, vtkDataAssembly provides several convenience methods to update the tree with ease.
It is possible to develop a mapper that uses the vtkDataAssembly. Using APIs that let users use path-queries to specify rendering properties for various nodes, the mapper can support use-cases where the input structure keeps changing but the relationships remain largely intact. Since the same dataset-index can be associated with multiple nodes in a vtkDataAssembly, the mapper can effectively support scene-graph-like capabilities where users can specify transforms, and other rendering parameters, while reusing the heavy datasets. The mapper can easily tell if a dataset has already been uploaded to the rendering pipeline since it will have the same id and indeed be the same instance even if it is being visited through
different branches in the tree.
3. How does the vtkPartitionedDataset and vtkPartitionedDatasetCollection fix the vtkMultiBlockDataSet issues
- Explicit Hierarchy
One of the main issues of the vtkMultiBlockDataSet is that its hierarchy is hidden inside itself. In order to know the hierarchy, one needs to browse the whole structure. By Making the hierarchy its own class (vtkDataAssembly), the vtkPartitionedDataSetCollection provides an API to construct, inspect and modify easily the hierarchy of a vtkPartitionedDataSetCollection.
- Distributed dataset constraints
As a vtkMultiblockDataSet, a vtkPartitionedDataSet can be shared across nodes in a distributed environment. However, there is nothing built in a vtkMultiBlockDataSet to ensure that data is consistent across nodes. With the vtkPartitionedDataSet, the consistency between partitions being mandatory filters can make a distinction between distribution of a dataset and different data, and exploit this information for their processing
- Conceptual separation
By separating the concept of vtkPartitionedDataSetCollection and vtkPartitionedDataSet, which were both supported by the vtkMultiBlockDataSet, the intention of the developers are much clearer, making the developments of distributed filters much simpler. This is a typical example where constraints drive quality.
4. How to use GroupDataSet and ExtractBlock with partitioned datasets collection in VTK/ParaView
GroupDatasets
Grouping multiple vtkDataSets into a vtkPartitionedDataSetCollection is as simple as using
GroupDataSet with the right settings.
- In ParaView
- Create multiple datasets
- Select all datasets to group together in the pipeline browser
- Add a GroupDatasets filter
- Select vtkPartionedDataSetCollection mode
- Apply
It is even possible to to create a vtkPartitionedDateSet this way and to group multiple
vtkPartitionedDatasets into a vtkPartionedDataSetCollection.
ExtractBlock
Extracting blocks from a vtkPartitionedDataSetCollection is as simple as using a ExtractBlock
filter with the right settings.
- In ParaView, with a vtkPartitionedDataSetCollection
- Add an ExtractBlock filter
- Select the blocks to extract
- Apply
Using VTK
// Group datasets together into a partitioned dataset collection
vtkNew<vtkGroupDataSetsFilter> grouper;
grouper->AddInputConnection(sphere0->GetOutputPort());
grouper->AddInputConnection(sphere1->GetOutputPort());
grouper->AddInputConnection(sphere2->GetOutputPort());
grouper->SetOutputTypeToPartitionedDataSetCollection();
// Extract the first and third block
vtkNew<vtkExtractBlockUsingDataAssembly> extractor;
extractor->SetInputConnection(edges->GetOutputPort());
extractor->AddSelector("/Root/Block0");
extractor->AddSelector("/Root/Block2");
5. How to create a simple vtkPartitionedDataSetCollection in VTK
Creating a simple vtkPartitionedDataSetCollection with a flat hierarchy is trivial in VTK
parts1->SetNumberOfPartitions(1);
parts1->SetPartition(0, dataset);
vtkNew<vtkPartitionedDataSet> parts2;
parts2->SetNumberOfPartitions(1);
parts2->SetPartition(0, dataset);
// Create a partitioned dataset collection
vtkNew<vtkPartitionedDataSetCollection> collection;
collection->SetPartitionedDataSet(0, parts0);
collection->SetPartitionedDataSet(1, parts1);
collection->SetPartitionedDataSet(2, parts2);
6. How to interact with PartitionedDataSetCollection in ParaView, including BlockColors and Select by block
In ParaView, vtkPartitionedDataSetCollection can be interacted with as with vtkMultiBlockDataSets. Any filter that can be applied to a vtkMultiBlockDataSet can be applied to a vtkPartitionedDataSetCollection, with the exception of the BlockScalars filter.
A dedicated filter lets you convert back to vtkMultiBlockDataSet in case it is needed, ConvertToMultiBlock.
All the rest behave as with vtkMultiBlockDataSets, including BlockColors, SelectByBlock, FindData and MultiBlockInspector.
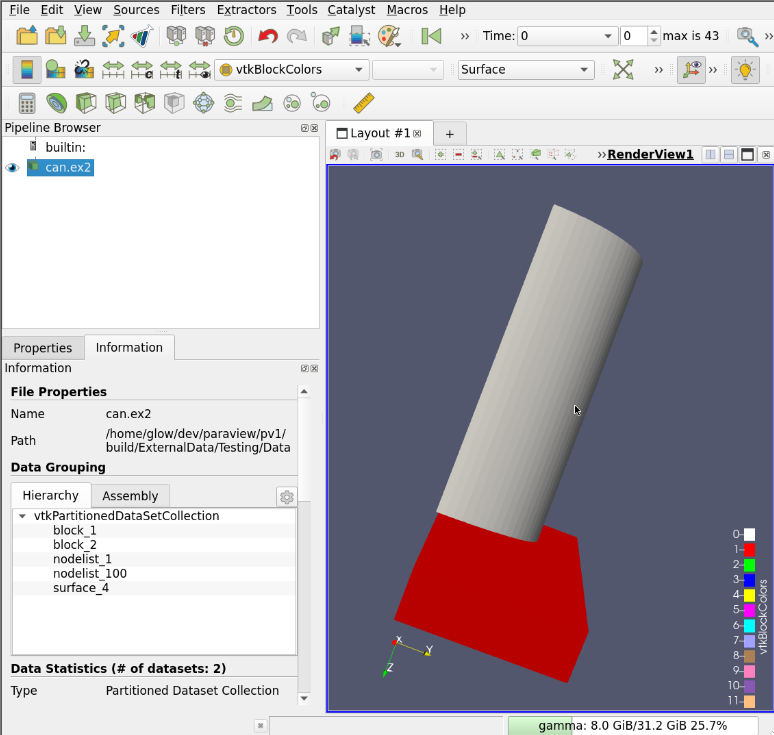
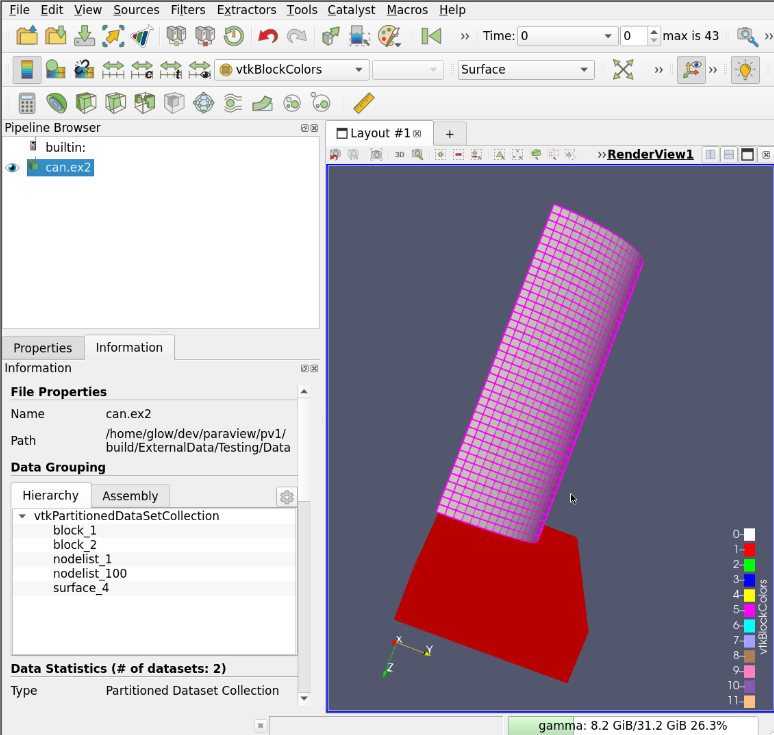
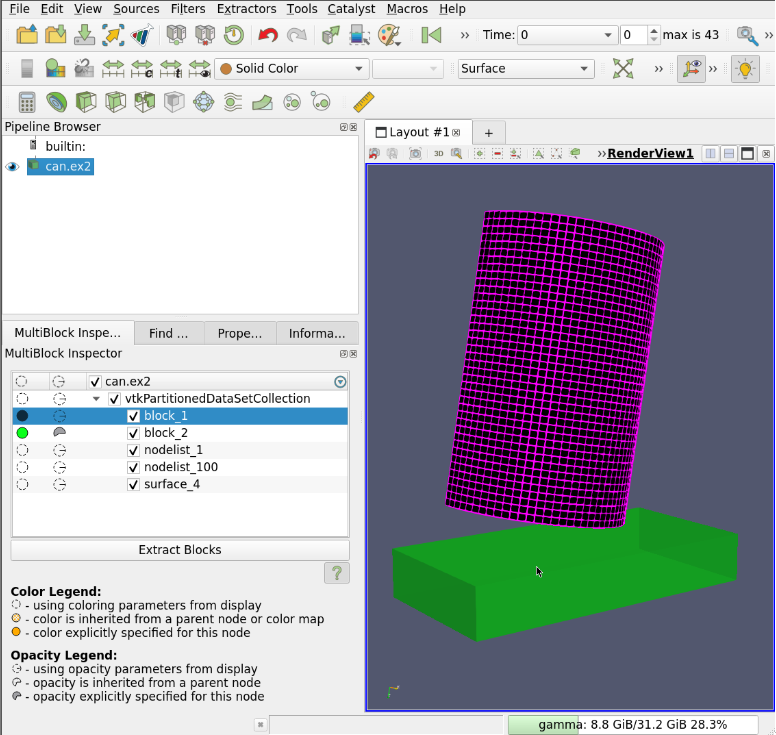
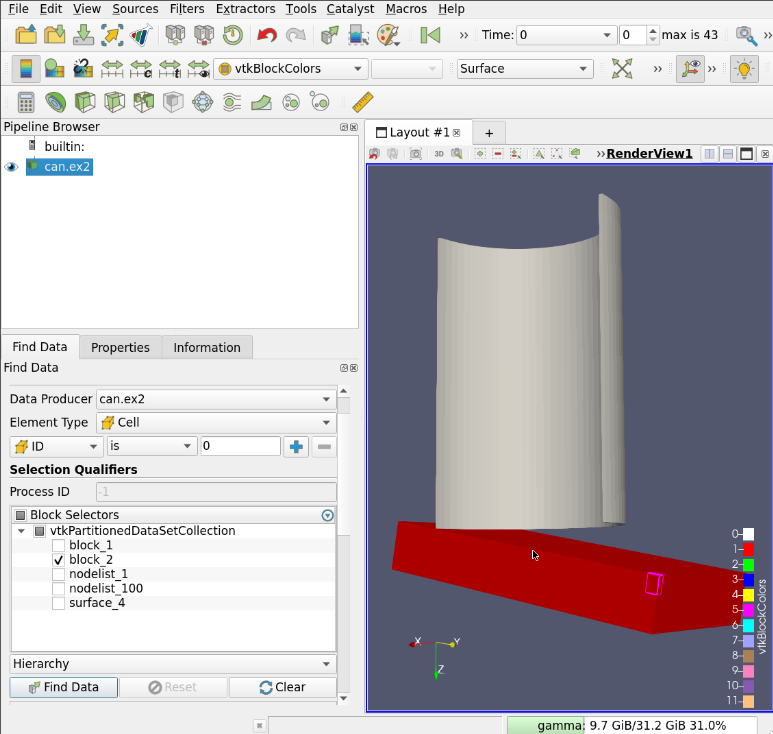
7. Changes in ParaView client API dues to the vtkPartitionedDataSet introduction
One of the main non-retro compatible change introduced by this are all the changes in vtkPVDataInformation that let client code inspect meta information about datasets, either vtkMultiBlockDataSet or vtkPartitionedDataSetCollection, with an unified API.
The previous API has just been removed without deprecation.
Here is an example usage in 5.9, how to print the names and number of points of the first level
blocks outputted by a source producing a vtkMultiBlockDataSet.
vtkSMSourceProxy* source = GetASource();
vtkPVDataInformation* sourceInfo = source->GetDataInformation();
vtkPVCompositeDataInformation* mbInfo =
source->GetCompositeDataInformation();
For (int i = 0; i < mbInfo->GetNumberOfChildren(); i++)
{
std::cout<<mbInfo->GetName(i)<<std::endl;
vtkPVDataInformation childInfo = mbInfo->GetDataInformation(i);
std::cout<<childInfo->GetNumberOfPoints()<<std::endl;
}
Here is an example usage in 5.11, how to print the names and number of points of the first level
blocks outputted by a source producing a vtkMultiBlockDataSet or a vtkPartitionedDataSetCollection.
vtkSMSourceProxy* source = GetASource();
vtkPVDataInformation* sourceInfo = source->GetDataInformation();
vtkDataAssembly hierarchy = mbInfo->GetHierarchy();
std::string rootSelector = “/” + hierarchy->GetRootNodeName();
for (int i = 0; i <
hierarchy->GetNumberOfChildren(vtkDataAssembly::GetRootNode()); i++)
{
std::string childName =
hierarchy->GetNodeName(hierarchy->GetChild(hierarchy->GetRootNode(), i);
std::cout<<childName<<std::endl;
vtkPVDataInformation* childInfo = source->GetSubsetDataInformation(0,
rootSelector + “/” +
childName)
std::cout<<childInfo->GetNumberOfPoints()<<std::endl;
}
8. Resources
- Initial deprecation post: Deprecating MultiBlock datasets
- VTK Data Assembly doc with links to all relevant classes
- ParaView Information API
9. Acknowledgments
This work was funded by EDF (Electricité de France) and SALOME Platform
