I have a simulation where I have several solid objects organized hierarchically (for example, wheels of a car). I want to enable live visualization using catalyst, and I want to create a vtkMultiBlockDataset hierarchy with vtkUnstructedGrid at the leaf.
I have two questions regarding this:
Is it possible to define that kind of hierarchy with conduit?
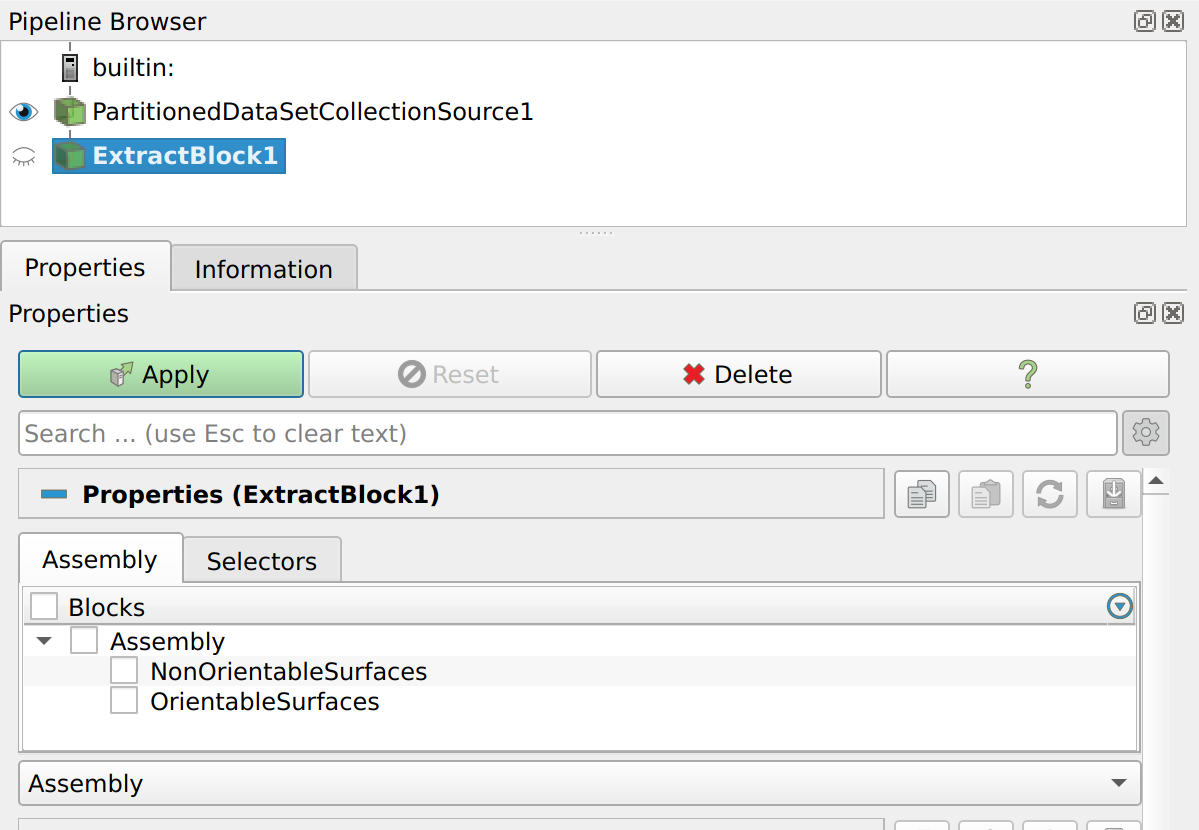
Let me explain. The first element is that the ParaView Conduit source (the output of Conduit if you will) is a Partitioned Dataset Collection. This is the new internal data format of VTK, used in place of Multiblock Datasets. This collection is a flat collection of datasets, as in, you cannot create put them at different level in a tree. This is by design. Instead, a tree of labels is created along side your data to define the hierarchy of your data. This is called the assembly node. To view an example of this, in ParaView, use source → PartitionedDataSetCollectionSource then Filters → ExtractBlock and select Assembly in the property pane instead of Hierarchy. You will see the tree of labels, which in this example only has one level.
Now back to Conduit. In your simulation code, you should put your data flat using the mesh blueprint, with one topology per object (one per wheel). You then create an assembly node in the blueprint containing the hierarchy of topology names.
Once on the ParaView side, each object can be extracted using the ExtractBlock filter and Assembly option.
Use ParaView to create your first Catalyst script. Load a result file from your simulation code, add a slice, then a VTPC extractor. Use file → save catalyst state. You will see that in the created python file, the file reader has been exported. That file reader has a registrationName=“something”. Replace the registration name content by the channel name you used on the simulation code side. Catalyst will use the Conduit channel instead of reading the file as the start of the pipeline.
Make sure you go through all the docs, as it can be a bit tricky to get started.
I have read the documentation several times and I still have doubts :-s
Right now I am exporting my simulation results in a custom format, based on HDF. I am in the process of exporting it as VTKHDF, now that it supports transient data, but I haven’t finished that migration yet.
To test, I have added a WavefrontReader to load a .obj file. If I just replace the registrationName, it will try to load the Conduit channel as if it was a OBJ? In the case of my custom file format, how will that work? Which readers can be used with Catalyst?
I’m not sure. My guess is that any reader will behave the same. The reader is essentially ignored by Catalyst and replaced by the ConduitSource. You could go through the vtk code and see if the Conduit Source has a python interface that you could use directly in the Catalyst script.
Okay! That was my main doubt, it is totally unclear how the data is fetched, in the different example in ParaView they use TrivialProducer, but I think this is not properly documented!
Do you know if its possible to remove the extractors? I dont really want to save anything to disk, my use case is to be able to watch the simulation while I am debugging the simulation code
Yeah, if you activate the live visualization, you probably don’t need the extractors. The option to activate the live visualization is given when you export a Catalyst state from ParaView.
Thanks, I think I have understand how this works. Ill create another thread if I have other doubts.
I have run a simple test changing the Reader type (from FastUniformGrid that is used in a test to WavefrontOBJReader) and yeah, it just gets ignored and the source type is in both cases a Partioned Dataset